Unicode 简介
Unicode 为现实世界的几乎所有语言的字符提供一个唯一的数字编码,被称为 码点 Code Point,不论是什么平台、不论是什么程序、不论是什么语言,都遵照这套码点规则,所以又被称作万国码。
Unicode 结构
结构范围
-
大小范围
-
Unicode 码点占用 4字节
-
Unicode 码点表示
一般地,采用
U+和十六进制形式码点组合来表示一个 Unicode 字符例如:汉字
书Unicode 表示为U+4E66 -
Unicode 码点范围 0x00000000 ~ 0x0010FFFF
0x 00 00 00 00 含义 分组 平面 行数 码位 注意:
虽然规划了四个字节,但实际使用的远未达到定义范围,例如:
最新的 Unicode®, 版本 10.0 规范 中,只用了其中的0~0x10FFFFIn the Unicode Standard, the codespace consists of the integers from 0 to 0x10FFFF, comprising 1,114,112 code points available for assigning the repertoire of abstract characters.
-
-
字节含义
在码点的四个字节中,按照高到底,每个字节取值 0 ~ 255
-
分组
最高一个字节,以 256 个平面构成一组,总共能构成 256 个组。
实际只用第 0 组,即:0x00nnnnnn -
平面
第二个字节,以
256 x 256的矩阵构成一个二维平面,
其中,前 256 为行数,后 256 为每行包含的码点个数,
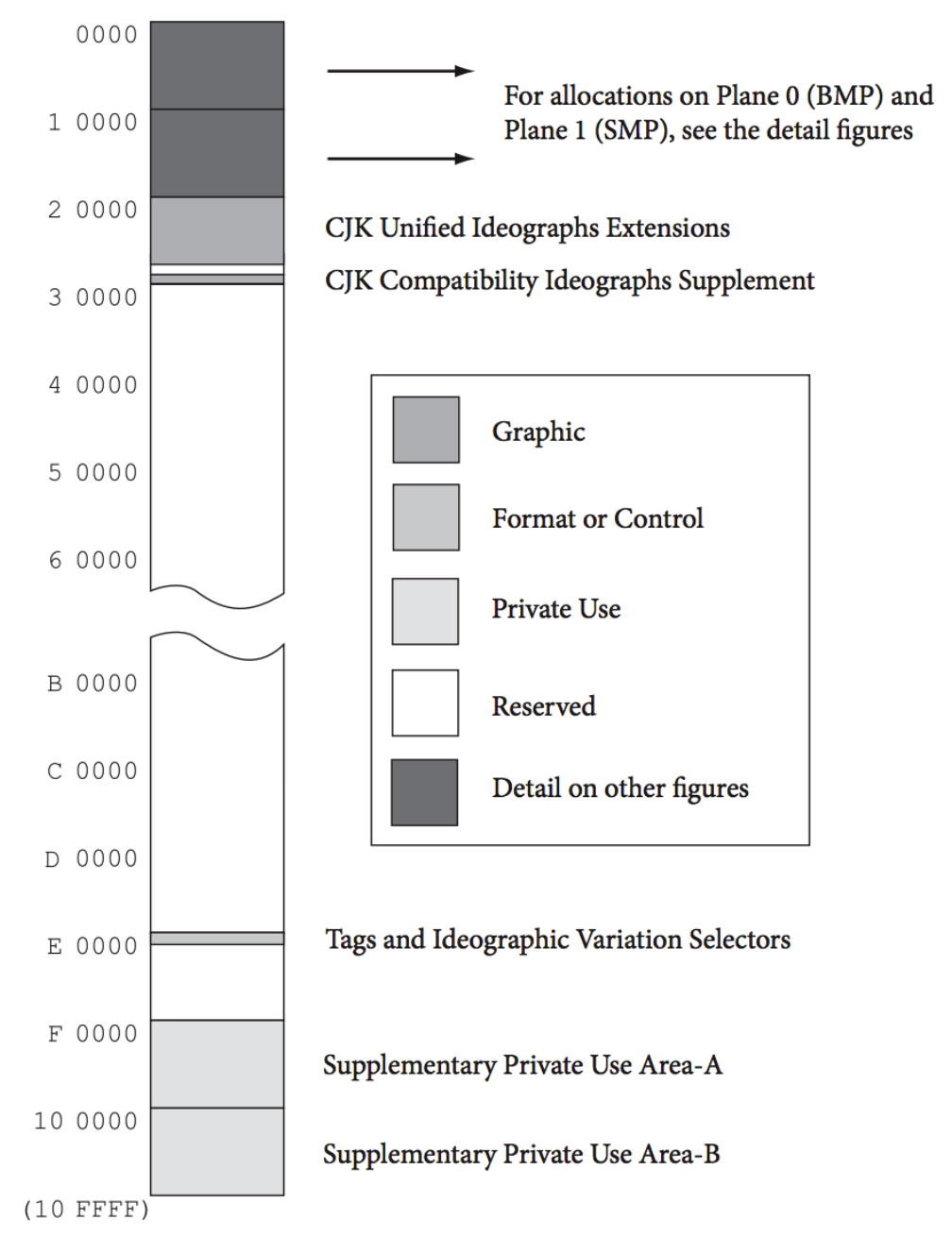
这样,一个平面就有 64k 码位,总共能包含 256 个平面。实际只使用了 0、1、2、14、15、16 这六个平面,详情参考一小节。
-
行数
第三个字节,表示所处平面的行号,有 0 ~ 255 共计 256 行。
-
码位
第四个字节,表示所处行中具体码号,有 0 ~ 255 共计 256个码号。
-
常用平面
-
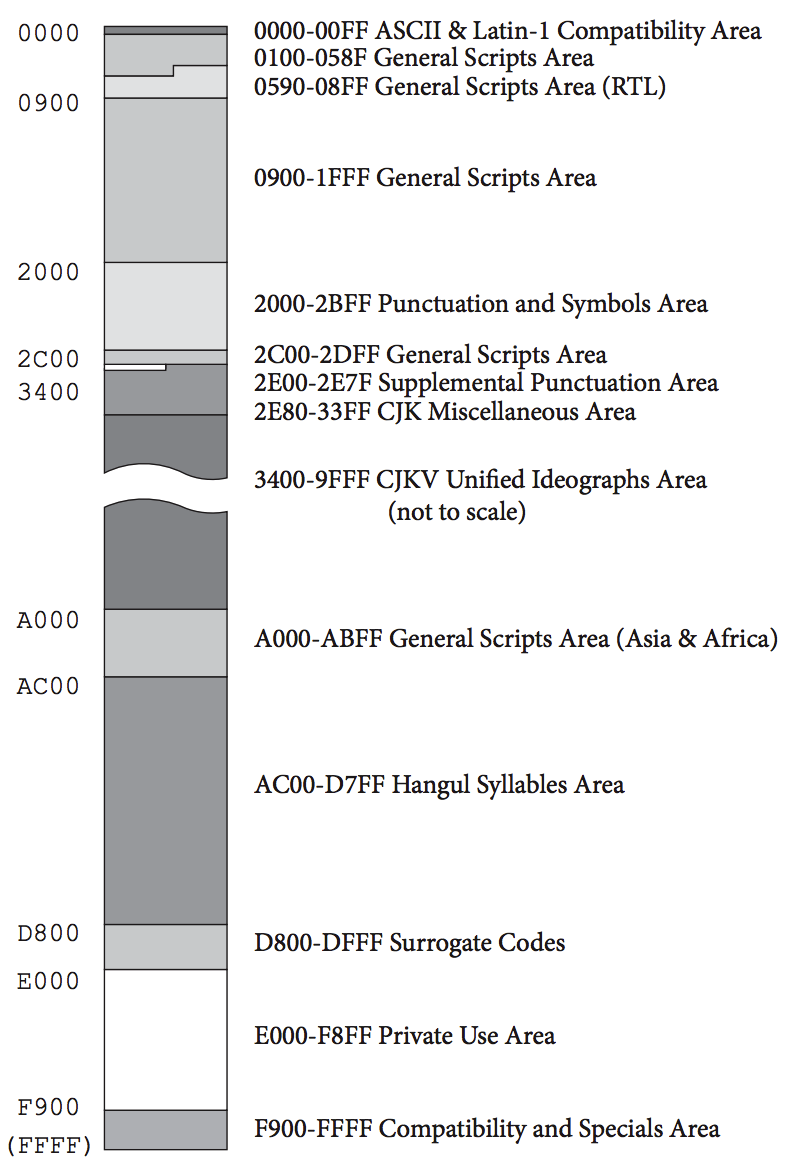
BMP( Basic Multilingual Plane )基本多语言平面
0 分组、0 平面,包含当代所有常用的的字符,又囊括许多古老的鲜有人用的字符。
到目前为止大部分的 Unicode 字符都能在这个平面找到。 -
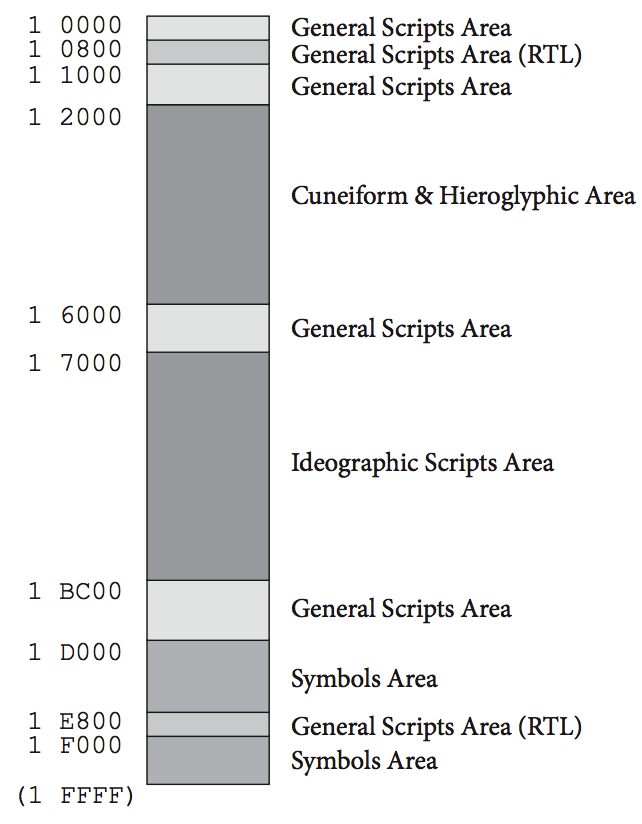
SMP( Supplementary Multilingual Plane )补充多语言平面
0 分组、1 平面,用于存放那些历史比较久远不常使用的字符或标记。
该平面字符记号不适合放入 BMP ,仅是对 BMP 进行补充及扩展。 -
SIP( Supplementary Ideographic Plane )补充表意平面
0 分组、2 平面,对 BMP 平面里 CJK( Chinese Japanese Korea )字符的额外分配区域,
该区域的字符与 BMP 中的 CJK 字符相比,不是很常用,除一小部分常用的广东方言文字。 -
SSP( Supplementary Special-purpose Plane )补充特殊目的平面
0分组、14平面,该平面式是一些特殊用途的格式控制字符,
由于 BMP 分给格式控制的码位区不够,故移动到该平面 -
PUP( Private Use Planes )专属使用平面
0分组、15、16两个平面,这两个平面共 113,068 个字符作为专属使用,
是对BMP里面的6400个字符的进一步扩从。
Unicode 编码
编码种类
-
单字节字符集 SBCS( Single Byte Character Set )
所有字符都只用一个字节表示,ASCII码就是使用该类型编码
-
多字节字符集 MBCS( Multi-Byte Character Set )
字符是由若干个字节表示,例如 UTF-8
-
Unicode 编码
所有字符都使用两个字节编码,UTF-16 是其中特例,UTF-16 是以 16 位为单位,
但是不限制一个字符只用 16 位,现在一般说的 Unicode 编码其实就是 UTF-16
Unicode 编码( 一般即 UTF-16 )
-
BMP 区(U < 0x10000)编码就采用 16 位无符号整数,格式
U+nnnn -
非 BMP 区(U ≥ 0x10000 )编码步骤如下:
-
将非 BMP 区的编码所包含的 20 bit,即 0x10000 ~ 0xFFFFF 1,分割为前后各 10 bit
-
取
110110、110111分别与前、后各 10bit 组合,构成两个U+Dnnn
前一个字节取值范围0xD800~0xDBFF
后一个字节取值范围0xDC00~0xDFFF为了让非 BMP 区字符(两个双字节)不与 BMP 区在(一个双字节)区分开,
BMP区中特别设置代理区(Surrogate),将0xD800~0xDFFF保留了下来。 此区间之所以称为高位专用代理区,正因其目的是映射其他非 BMP 平面,例如: PUP 专属使用面,即平面 15、16,也被编码为两个双字节。当然,Unicode 除了可以使用 UTF-16 外,还有更为灵活的 UTF-8 编码,
以及与Unicode码点一一对应的UTF-32编码。由于 UTF-16 采用 16 bit 和代理技术,能够囊括全部 Unicode 码点,
一般而言都会采用 UTF-16 ,例如:JVM 内部字符就采用此编码。
当然也有采用 UTF-8 编码方案,例如:Windows、大部分Linux。
-
UTF-8 编码
| Unicode 范围 (十六进制) | UTF-8 字节序列 (二进制) |
|---|---|
| 0000 0000 ~ 0000 007F | 0xxxxxxx |
| 0000 0080 ~ 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 ~ 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 ~ 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-32 编码
固定四个字节 U+nnnnnnnn 缺点显而易见,数据冗余太大,故很少使用。
Unicode 编码格式检测
由于 Unicode 编码为四字节正整数,不同结构的计算机在存储改编码时就会遇到大小端问题。
-
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中, 这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放。
-
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中, 这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
为了让计算机正确读取 Unicode 编码的文件数据,就需要某种方式告诉计算机数据的字节序。
BOM( Byte Order Mark) 字节序标志头就孕育而生。
| UTF 编码 | Byte Order Mark |
|---|---|
| UTF-8 | EF BB BF (非必须) |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
脚注
-
Unicode 最大取值减 SMP 最小取值 ,即
0x10FFFF - 0x10000 = 0xFFFFF↩





