第八章 泛型程序设计
为何使用泛型程序设计
- 泛型程序设计意味着编写的
代码可以被不同类型的对象重用- Java SE 5.0之前:
泛型是通过继承实现,导致需要强制类型转换、缺失编译时类型检测 - Java SE 5.0之后:
引入类型参数,代码可读性、安全性提高,可提供编译时类型检测
- Java SE 5.0之前:
- 泛型程序设计3个能力级别
- 使用泛型类
- 学习泛型解决旧代码与泛型的衔接
- 实现自己的泛型类及方法
简单泛型类
泛型类是具有一个或多个泛型变量的类
- Java库中常用的类型变量
E:集合的元素类型K:映射中的关键字V:映射中的值类型T、U、S:任意类型
声明一个泛型类:
public class Pair<T> { }
泛型方法
语法:
// 方法声明,类型参数定义及类型参数变量放在 修饰符 与 返回类型 之间
public static <T> T getMiddle(T.. a) { }
// 方法调用
String middle = obj.<String>getMiddle("parm1", "parm2")
注意:
-
Java SE 7之后,只要能推断出变量类型的地方都可以省略,如:
ArrayList<String> list = new ArrayList<>(); obj.getMiddle(...); -
当传入参数有不同类型时,编译器会找出共同的超类型,有多个共同超类时报错,如:
/* * 编译器解析为:Double, Integer, Integer,共同超类有 * Number、Comparable,此时编译不通过 */ double middle = obj.getMiddle(3.14, 1729, 0); // 解决办法改为这样调用 double middle = obj.getMiddle(3.14d, 1729d, 0d);另:如果调用语句没有被赋值给变量时,编译器不报错,默认选择Number类型
obj.getMiddle(3.14, 1729, 0);
类型变量的限定
语法:
<T extends BoundingType>
其中,BoundingType 可以是由&分隔的多个限定类型
例如:Comparable & Serializable
注意:
多个限定类型中,至多只能有一个类且要放在第一个,接口没限制
泛型代码和虚拟机
虚拟机没有泛型类型的对象,所有对象都属于普通类
早期泛型实现甚至能向后兼容,只是最后放弃了向后兼容性
-
泛型擦除
无论何时定义一个泛型,都自动提供一个相应的原始类型
擦除规则如下:- 无限定类型时,将T类型转换成Object
例如:- 类:
class Pair<T>–>class Pair - 方法:
public T getFirst()–>public Object getFirst()
- 类:
- 有限定类型时,类型单一转换为该类型,多个时转成第一个类型其余强制转换
例如:- 类:
class Interval<T extends Comparable & Serializable>
–>
class Interval - 方法:
public Interval(T first, T second)
–>
public Interval(Comparable first, Comparable second)
注意:
如果声明时,Serializable 在前那么构造方法将使用该类型
需要比较时还得强制转换为 Comparable ,出于提高效率一般都
将标签接口放在边界列表的末尾 - 类:
- 无限定类型时,将T类型转换成Object
- 翻译表达式
编译器将方法调用翻译成两条虚拟机指令- 对泛型擦除后原始类型的方法调用
- 将返回的原始类型强制转换成实际需要的类型
-
翻译泛型方法
将方法按照方法擦除的规则进行翻译,必要时进行强制转换
方法翻译会出现一个有趣的合成桥方法现象,具体请看如下例子:class Pair<T> { public void setSecond(T second) { ... } public T getSecond() { ... } } class DateInterval extends Pair<LocalDate> { public void setSecond(LocalDate second) { ... } pubilc LocalDate getSecond() { ... } }DateInterval 的 setSecond 方法是否是对父类 Pair 方法的覆盖?
提出这个问题估计要被鄙视,用
@Override标注后顺利通过,当然是覆写啦!
那我们来深入分析一下,问题其实远没有表面上那么简单:-
将父类 Pair 泛型进行擦除后,原始类型为
class Pair { public void setSecond(Object second) { ... } } -
对比不难发现,子类所谓的覆写方法完全构不成覆写,参数类型不匹配
-
但尝试使用多态方式调用,发现还真能调用到子类的 LocalDate 方法
Pair<LocalDate> p = new DateInterval(); p.setSecond(LocalDate.now());
诡异,明明不符合方法覆写规则,但竟被认为是覆写方法!
其实,幕后始作俑者为编译器,它使用桥方法来解决泛型方法擦除后与子类覆写的冲突问题编译器发现对子类的 set 方法参数为 LocalDate 肯定是最恰当的
而父类参数擦除后参数为 Object 也是无可厚非,为了能够多态的调用子类的恰当方法
编译器在子类中合成了桥方法连接真实的覆写方法和最恰当的方法// 此为编译器添加的隐藏桥方法 public void setSecond(Object second) { setSecond((LocalDate) second); // 强制转换调用恰当的方法 } // 此为编译器添加的隐藏桥方法 public Object getSecond() { // 这个方法更诡异,同类中有同名同参数方法 return getSecond(); }子类中存在参数不同的set方法没啥问题,符合重载规范,诡异的是get方法
方法名、参数类型都一样只是返回类型不同,明显不符合重载规范当然,我们自己写这两个get方法是不合法的,此get方法是由编译器合成的
况且,虚拟机确定一个方法是参数类型和返回类型都考虑,故没问题以上分析可得知,显示在代码中的LocalDate方法准确的说不是覆盖方法,
而真正的覆盖方法是编译器合成的桥方法,再由其调用显示的方法出现桥方法可不止这一种情形,下面几种情况都会出现桥桥方法:
- 子类覆盖泛型父类的方法(即本例)
- 方法覆盖父类,返回值类型比父类更严苛时
- 内部类访问外部类的成员及方法
注意:
桥方法 与 引导方法(Bootstrap Method) 的区别,引导方法出现在 lambda 方法的调用中
为调用 lambda 方法,引导方法需要做一些前期准备工作,引导方法的名称由此得来总结
- 虚拟机中没有泛型,只有普通的类和方法
- 所有的类型参数都用它们的限定类型替换
- 桥方法被合成来保持多态
- 为保持类型安全性,必要时插入强制类型转换
-
-
调用遗留代码
泛型类型被设计出来就允许泛型代码与遗留代码之间能互相操作
互操作时,编译器会有警告信息发出但其实这并不是因为引入泛型后出现了安全性问题
恰恰相反,没引入泛型时这些安全性问题同样存在但编译器无法发现这种类型安全隐患
引入泛型后,编译器获得了发现隐患的能力故而可以给予警告提示一般遇到警告,操作规则为:
- 检查旧代码,确保对泛型的对象没有作出违反泛型类型协定的操作
- 排除类型安全隐患后,使用
@SuppressWarings(unchecked)注解取消警告
约束与局限性
-
参数类型不能是基本类型,擦除后的的类是包含Object,而Object无法存储基本类型
-
运行时类型检测只适用于原始类型
if (a instanceof Pair<String>){} // 错误,运行时其实只能判断是否是Pair类 if (a instanceof Pair<T>){} // 错误,运行时其实只能判断是否是Pair类 Pair<String> p = (Pair<String>) a; // 警告,运行时只能判断是否是Pair类 // 如果a引用是个 Pair<Integer>类型,编译时能够检测出类型不匹配 Pair<String> p = (Pair<String>) a; // 错误,类型不匹配 // 如果a引用是个 Pair原始类型且存储的是Integer的,编译时运行时都检测不出 Pair a = new Pair<Integer>(); Pair<String> p = (Pair<String>) a; // 警告,运行时也能被赋值 //直到运行这段代码才会在多态调用中的发现类型不匹配报错 p.setSecond("put String into Integer error"); -
不能创建参数化类型的数组
数组有个机制能够记住它的元素类型,试图存入其他类型会抛
ArrayStoreException
但是参数化数组由于运行时擦除,使得数组的此机制失效故而编译器禁止创建参数化数组例如:
Integer[] iArray = new Integer[10]; Object[] oArray = iArray; oArray[0] = "String"; // ArrayStoreException Pair<String>[] table = new Pair<String>[10]; // 假装能这样创建参数化数组 Object[] objArray = table; objArray[0] = new Pair<String>(); // 代码一 objArray[1] = new Pair<Employee>(); // 代码二代码一和代码二在运行时擦除了参数类型,都为 Pair 类型,数组会认为合法
其实这两对象的数据完全不同,为了避免这样的隐患,所以不能 new 出参数化数组变通的做法:
Pair<String>[] table = (Pair<String>[]) new Pair<?>[10]; // 或 Pair<String>[] table = (Pair<String>[]) new Pair[10]; // 或更安全的 ArrayList<Pair<String>> table = new ArrayList<>();当 可变参数 为参数化类型的时候,就不可避免的需要虚拟机创建泛型数组
虽然规则禁止用户代码创建泛型数组,但规则对虚拟机还是有所放松,改为警告提示
当确认警告的代码安全(安全指擦除后的所有对象均类型一致,将来修改代码仍有安全隐患)
可使用如下方式消除警告:@SuppressWarnings("unchecked") public static <T> void addAll(Collection<T> coll, T... ts) // Java SE 7之后还可以采用 @SafeVarargs public static <T> void addAll(Collection<T> coll, T... ts) -
不能实例化类型变量
错误示范:
new T(...)、new T[...]、T.class正确示范:
-
传统反射法
public static <T> Pair<T> makePair(Class<T> cl) { try { return new Pair<>(cl.newInstance(), cl.newInstance()); } catch(Exception ex) { return null; } } Pair<String> p = Pair.makePair(String.class); -
JavaSE 8方法表达式
public static <T> Pair<T> makePair(Supplier<T> constr) { return new Pair<>(constr.get(), constr.get()); } Pair<String> p = Pair.makePair(String::new);
-
- 不能构造泛型数组
-
传统反射法
public static <T extends Comparable> T[] minmax(T... a) { Object obj = Array.newInstance(a.getClass().getComponentType(), 2); return (T[]) obj; } String[] strs = Pair.minmax("Tom", "Dick"); -
JavaSE 8方法表达式
public static <T> T[] minmax(IntFunction<T[]> constr, T... a) { return constr.apply(2); } Pair<String> p = Pair.makePair(String::new, "Tom", "Dick"); -
当不知道元素类型还要生成一个T[]数组时,ArrayList是这样处理的:
T[] toArray(T[] result);引入一个类型数组,如果数组足够大,使用此数组装元素
否则用result元素的类型构造新数组,填充元素
-
-
静态域或方法中不能引入非静态的类型变量
例如:
public class Singleton<T> { // 此处声明非静态的类型变量 private static T singleInstance; // error 不能引用非静态类型变量 public static T getSingleInstance() { // error return singleInstance; } // 注意区别如下静态类型变量 public static <U> U methodName() { // 此处声明的U为静态类型变量 return (U) obj; } // 类型参数的定义可以出现在 类名后的<> 或者 方法修饰符后返回参数之前的<> } -
不能抛出或捕获泛型类的实例,泛型扩展Throwable也被禁止
泛型类的实例 指错误或异常类是泛型的形式,如
SomeException<T>
其实泛型类不允许扩展 Throwable ,就没有泛型异常类,就更没泛型异常类的实例特别的:catch子句不能使用 类型变量 (Type Parameter)
Tips:
类型变量 vs 类型参数 类型变量(Type Parameter):FooClass<T> 这里的T就是类型变量 类型参数(Type Argument):FooClass<String> 这里的String就是类型参数例如:
public class Problem<T> extends Exception {} // 错误 try { } catch (T e) {} // 错误,catch块不允许类型变量(Type Parameter) // 抛出类型变量是被允许的 public static <T extends Throwable> void doWork(T t) throws T { // 被允许 try { // do work } catch (Throwable cause) { t.initCause(cause); throw t; // 被允许 } } -
消除编译器对受检查异常的检查
// 此段代码能够掩盖所有的受检查异常,逃避编译器的受检异常检查 @SuppressWarnings("unchecked") public static <T extends Throwable> void throwAs(Throwable e) throws T { throw (T) e; } 调用示例: try { // 可能抛出任何受检查异常的代码 } catch (Throwable t) { ClassName.<RuntimeException>throwAs(t); } 此代码用在Thread的run方法很合适,避免对受检异常的捕获,因为run方法不允许受检异常抛出的 -
一个类不能同时成为两个实现了同一接口的不同参数化的泛型类型的接口类型的子类
是不是有点拗口,看例子:interface A implements Comparable<String> { ... } interFace B implements Comparable<Integer> { ... } // 接口A、B实现了相同接口不用类型参数的接口,此时C是不能同时实现A、B的 Class C implements A, B { ... } // 深究原因,应该是这样编译器生成A、B的合成桥方法会有冲突 // 如果A,B为非泛型版本的接口,C类就不会有合成桥方法的冲突,就是合法的
通配符类型
-
通配符类型允许类型参数变化,较固定的泛型类型更灵巧
例如:printBuddies(Pair<Employee> p)不接受Pair<Manager>的参数
然而Pair<? extends Employee>是能够接受继承关系为:
Pair(原始类型) |- Pair<? extend Employee> (通配符类型) |- Pair<Manager> (通配符的子类) |- Pair<Employee> (通配符的子类) -
子类限定与超类限定
子类限定:
? extends Employee
超类限定:? super Manager有超类限定的通配符可以向泛型对象安全写入,有子类限定的通配符可以从泛型对象安全读取。
这里有涉及协变与逆变相关知识,可以大概了解下,Java是支持协变的返回类型的
-
无限的通配符
Pair<?> 与 Pair 的区别: Pair<?> 是无限通配符类型,Pair 是原始类型
? getFirst()返回值只能赋值给Objectvoid setFirst(?)压根就不能被调用,即使原始的 Object 对象也无法调用void setFirst(Object)此为原始版本,所有 Object 对象都可调用
使用Pair<?>这样脆弱的类型对于许多简单的不需要实际类型的操作很有用,例如:
// 调用此方法压根不需要参数类型,相反如果是泛型类型传入原始类型是会有警告提醒的 boolean hasNulls(Pair<?> p) { return p.getFirst() == null || p.getSecond() == null; } // 泛型类型可读性没通配符的强 <T> boolean hasNulls(Pair<T> p) { return p.getFirst() == null || p.getSecond() == null; } -
通配符捕获
有些时候要知道通配符的具体类型时,就一定要对通配符类型进行捕获,例如:// 编写一个交换两个元素的方法,在存储临时一个元素时,一定要知道元素具体类型 public static void swap(Pair<?> p) { /* ? tmp = p.getFirst(); // 编译错误 p.setFirst(p.getSecond()); p.setSecond(t); */ // 通过增加一个swapHelp来帮助捕获具体'?'的类型 swapHelp(p); } public static <T> void swapHelp(Pair<T> p) { T tmp = p.getFirst(); p.setFirst(p.getSecond()); p.setSecond(t); }通配符捕获必须要让编译器能够确信通配符表达的是单个、确定的类型,像这样:
ArrayList<Pair<T>>是无法捕获ArrayList<Pair<?>>当中的通配符因为,ArrayList<Pair<?>>中是可以同时包含:
ArrayList<Pair<String> >和ArrayList<Pair<Integer> >那么
T到底捕获String还是Integer不得而知,编译器就不让通过了
反射和泛型
泛型类型的对象,由于泛型擦除机制所以反射时得不到太多的信息。
泛型Class类可以是反射与泛型之间的纽带,例如:
String.class实际是Class<String>的唯一对象
可以巧借Class<T>参数进行类型匹配,例如:
public static <T> Pair<T> makePair(Class<T> c) throws
InstantiatioinException {
return new Pair<>(c.newInstance(), c.newInstance());
}
可以使用反射API来确认:
- 泛型方法有叫 T 的类型参数
- 这个类型参数 T 有一个子类限定,且限定的类又是一个泛型类
T extends Type<T> - 限定类型有一个通配符参数
? - 这个通配符参数有一个超类型限定
? super Type - 这个通配符参数有一个子类型限定
? extends Type - 这个泛型方法有一个泛型数组参数
T[]
针对上面的情况,java.lang.reflect 包提供接口 Type,包含下列子类型:
- Class类,描述具体类
- TypeVariable接口,描述类型变量
T extends Comparable<? super T> - WildcardType接口,描述通配符
? super T - ParameterizedType接口,描述泛型类或接口类型
Comparable<? super T> - GenericArrayType接口,描述泛型数组
T[ ]
下面程序清单是利用反射API,动态获取某个类的所有方法定义:
package generic;
import java.lang.reflect.GenericArrayType;
import java.lang.reflect.Method;
import java.lang.reflect.Modifier;
import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
import java.lang.reflect.TypeVariable;
import java.lang.reflect.WildcardType;
import java.util.Arrays;
import java.util.Scanner;
public class Print {
public static void main(String[] args) {
String name;
if (args.length > 0) name = args[0];
else {
try (Scanner in = new Scanner(System.in)) {
System.out.println("请输入类的全限定名(如:java.lang.String):");
name = in.next();
}
}
Class<?> c;
try {
c = Class.forName(name);
printClass(c);
for (Method m : c.getDeclaredMethods()) {
printMethod(m);
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
// 打印类声明信息
private static void printClass(Class<?> c) {
System.out.print(c);
// 打印类的类型参数数组
printTypes(c.getTypeParameters(), "<", ", ", "> ", true);
// 打印父类对象
Type t = c.getGenericSuperclass();
if (t != null) {
System.out.print(" extends ");
printType(t, false);
}
// 打印所实现的接口
printTypes(c.getGenericInterfaces(), " implements ", ", ", "", false);
System.out.println();
}
// 打印方法声明
private static void printMethod(Method m) {
String name = m.getName();
// 获得修饰符
System.out.print(Modifier.toString(m.getModifiers()) + " ");
// 打印方法的类型参数数组
printTypes(m.getTypeParameters(), "<", ", ", "> ", true);
// 打印返回类型
printType(m.getGenericReturnType(), false);
System.out.print(" " + name + "(");
// 打印方法的所有参数的类型
printTypes(m.getGenericParameterTypes(), "", ", ", "", false);
System.out.println(")");
}
// 打印类型数组
private static void printTypes(Type[] types, String pre, String sep,
String suf, boolean isDefinition) {
// 默认继承Object时,默认不打印出来
if (pre.equals(" extends ") && Arrays.equals(types, new Type[] { Object.class } )) return;
if(types.length > 0) System.out.print(pre);
for(int i=0; i<types.length; i++) {
printType(types[i], isDefinition);
if (i < types.length-1) {
System.out.print(sep);
}
}
if(types.length > 0) System.out.print(suf);
}
// 打印单个类型
private static void printType(Type type, boolean isDefinition) {
if (type instanceof Class) { // 一般类型
Class<?> c = (Class<?>) type;
System.out.print(c.getName());
} else if(type instanceof TypeVariable) { // 类型变量 T extends Type & Type
TypeVariable<?> t = (TypeVariable<?>) type;
System.out.print(t.getName());
if (isDefinition)
printTypes(t.getBounds(), " extends ", " & ", "", false);
} else if(type instanceof WildcardType) { // 通配符类型 ? super|extends Type & Type
WildcardType t = (WildcardType) type;
System.out.print("?");
printTypes(t.getUpperBounds(), " extends ", " & ", "", false);
printTypes(t.getLowerBounds(), " super ", " & ", "", false);
} else if(type instanceof ParameterizedType) { // 泛型类或接口 ClassName<Type>
ParameterizedType t = (ParameterizedType) type;
Type owner = t.getOwnerType(); // 内部类的所有者
if (owner != null) {
printType(owner, false);
System.out.print(".");
}
printType(t.getRawType(), false);
printTypes(t.getActualTypeArguments(), "<", ", ", "> ", false);
} else if(type instanceof GenericArrayType) { // 泛型数组 T[]
GenericArrayType t = (GenericArrayType) type;
System.out.print("");
printType(t.getGenericComponentType(), isDefinition);
System.out.print("[]");
}
}
}
第九章 集合
Java集合框架
-
迭代器
Java迭代器位于两个元素之间,调用next方法,迭代器越过下一个元素并返回该元素
next与remove调用具有互相依赖性,不能连续调用两次remove -
集合框架中的接口
Iterable |-- Collection |-- List |-- Set | |-- SortedSet | |-- NavigableSet |-- Queue |-- Deque Map |-- SortedMap |-- NavigableMap Iterator |-- ListIterator RandomAccess (Java SE 1.4加入,标记集合支持高效的随机访问)-
随机访问:
使用整数索引来访问元素,集合的数据结构不同随机访问性能差异很大
一般实现了RandomAccess接口的采用随机访问更高效 -
顺序访问:又称迭代器访问,必须顺序的访问元素
-
Set接口
Set与Collection接口类似,但不允许有相同元素
equals、hashCode方法要保证元素顺序不同不影响方法结果
-
具体的集合
| 集合类型 | 描述 |
|---|---|
| ArrayList | 可以动态增加和缩减的索引序列 |
| LinkedList | 可以在任意位置高效插入、删除的有序序列 |
| ArrayDeque | 循环数组实现的双端队列 |
| HashSet | 没有重复元素的无序集合 |
| TreeSet | 有序集 |
| EnumSet | 枚举类型的集 |
| LinkedHashSet | 可以记住元素插入次序的集 |
| PriorityQueue | 高效删除最小元素的集合 |
| HashMap | 存储键值对的数据结构 |
| TreeMap | 键值有序排列的映射表 |
| EnumMap | 键值是枚举类型的映射表 |
| LinkedHashMap | 可以记住键值加入次序的映射表 |
| WeakHashMap | 值无用武之地后可以被垃圾回收器回收的映射表 |
| IdentityHashMap | 用==号比较键值的映射表 |
Java Collections Framework Internals
-
链表列表
Java中,所有的链表都是双向链表,即存放着这前序、后序的引用
链表按索引操作时,索引在链表前半部分头到中间遍历,反之用尾到中间遍历
基于此原因,随机访问一般不用链表结构,效率低由于List是有序的集合可以使用
ListIterator的add(E)方法添加元素
由于Set是无序集合,元素与添加顺序无关故而只能使用无add(E)的Iteratorset方法不算结构性改变,故而不在并发修改的检测范围 -
数组列表
动态数组的实现包含
ArrayList、Vector两个类,后者是线程安全的
数组列表在随机访问上效率高 -
散列集
散列集采用链表数组实现,每个链表被称为桶(Bucket)
想要知道对象obj在链表数组那个索引,采用如下公式:
index = obj.hashCode() % AMOUNT_OF_BUCKET
关于hashCode值的算法,参考《Effective Java》第二版第9条散列冲突指被操作的对象通过公式得到的那个桶已经存在其他对象
Java SE 8开始桶满时会从链表变为平衡二叉树标准类库中默认桶数16,传入其他值时自动转化为最接近的下一个2的次幂
装填因子决定何时对列表进行再散列(即桶数扩大重装数据,丢弃原散列表)
默认装填因子为0.75,即表中超过75%的位置已有数据时进行再散列
更改集中的元素如引起散列码的改变,元素在数据结构中的位置也会发生变化 -
树集
树集是一个有序集合,任意顺序插入集合得到的都是排序后的结果
由于需要比较排序,添加元素的时候效率略低于散列集 -
队列、双端队列与优先级队列
队列是可以在尾部添加在头部删除的数据机构,双端队列头尾都可以添加或删除
优先级队列利用堆(可自我调整的二叉树)数据结构,无论添加或删除都可让最小
元素移动到根而不必花费时间对元素进行排序,PriorityQueue为优先队列 -
映射
HashMap和TreeMap是映射的两个实现,不同在于后者会根据键值排序WeakHashMap里的Entry对象即使没用调用remove方法也有可能被GC清除IdentityHashMap的键散列值是根据对象的内存地址来计算的
Object的默认hashCode方法也是如此计算的
不使用hashCode函数,故而对象比较时使用==运算符LinkedHashSet与LinkedHashMap都能记录元素的插入顺序
如果需要按访问顺序进行迭代,那么可以调用如下构造方法:
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder)
最后一个参数传递true可将最近访问元素放到链表最后,实现最近最少使用算法LRU
-
视图与包装器
HashSet是HashMap的一个包装类,map里的所有key的value值都是相同对象 像这样的包装我们可以认为HashSet是内部HashMap的一个视图
Map类的KeySet初看好像是一个新集,其实返回的是一个实现Set,内部方法还是
对原Map进行操作的,像这种的集合称作视图,常见的返回包装器的方法:// 只运行get、set,试图改变原数据结构的add、remove方法将会抛出异常 List<T> Arrays.asList(T... t) // 将单个对象映射成一个不可改变的List List<T> Collections.nCopies(n, T) // 以下的几个截取子范围的结构改变操作可以反映到原始数据结构中 List<T> list.subList(E from, E to) Sorted[Set|Map]<E> [set|map].subSet(E from, E to) Sorted[Set|Map]<E> [set|map].headSet(E to) Sorted[Set|Map]<E> [set|map].tailSet(E from) // Java SE 6引入的截取还包含是否包含左右边界的布尔值 NavigableSet<E> set.subSet(E from, boolean fInc, E to, boolean tInc) NavigableSet<E> set.headSet(E to, boolean tInc) NavigableSet<E> set.tailSet(E from, boolean fInc) /* * 防修改视图,其中XXX代表Collection、List、Set、SortedSet、 * NavigableSet、Map、SortedMap、NavigableMap */ XXX Collections.unmodifiableXXX(XXX) /* * 同步视图,其中XXX代表Collection、List、Set、SortedSet、 * NavigableSet、Map、SortedMap、NavigableMap */ XXX Collections.synchronizedXXX(XXX) /* * 受查视图,其中XXX代表Collection、Queue、List、Set、SortedSet、 * NavigableSet、Map、SortedMap、NavigableMap */ XXX Collections.checkedXXX(XXX)注意:
Collection这层无法多态调用equals,只能用Object默认的,因为有可能是List和Set进行比较
算法
-
链表结构不要用随机访问(get、set)应该用迭代器
-
集合框架的排序采用的是归并排序,而没用通常的快速排序因为归并排序
不会交换相同元素,某种情况下进行不必要的交换被视为不稳定,例如: 已经按照名称排序的员工列表改为按工资进行重拍,归并能保证工资相同的
员工名称依然是有序的 -
二分查找时,遇到链表结构时改为线性查找,故支持随机访问的集合二分算法更有意义
-
集合与数组的转换有两种形式,区别在于返回的是否是确切的特定类型
Object[] c.toArray() T[] c.toArray(T[]) -
采用位集(BitSet)实现的 Eratosthenes 筛子算法查找素数蛮好
位集的get(int)、set(int)、clear(int)、and|or|xor|andNot(BitSet)
对于获得、设置、清除以及一些逻辑操作,设置即将该位置1
第十章 图形程序设计
略
在多线程章节有涉及GUI的绘制问题,故先理解下有关paint的概念
- 重量级与轻量级组件
组件牵扯到本地操作系统的窗口的组件被称作重量级组件,反之则为轻量级 - 触发组件绘制的两种类型
- 本地系统触发
- 组件初次展现在屏幕时
- 组件改变大小
- 组件遭到破坏需修复时,如:原本被遮挡的组件重新显示时
- 应用程序自身触发 由于程序改变组件的状态而需要重绘时
- 本地系统触发
-
AWT绘制机制
AWT采用方法回调机制来处理绘制,该方法称作paint(Graphic g)
回调时所提供的Graphic对象已经预设好对当前组件合适的参数
程序应该极力避免在回调机制外直接调用paint方法,因为可能无法提供合适的Graphic
程序应该使用repaint方法,复杂情况下使用其重载的带参数的版本来减少重绘数量- 系统触发的重量级组件绘制机制
- AWT决定容器中的部分或全部的组件需要绘制
- AWT触发事件分发线程(Event Dispatching)去调用每个组件的
paint方
- 程序触发的重量级组件绘制机制
- 程序改变组件的状态从而决定容器中的部分或全部的组件需要绘制
- 程序调用组件的
repaint,由其向AWT注册一个异步绘制请求 - AWT再触发时间分发线程去调用每个组件的
update方法
-
update与paint区别
对重量级组件而言,update方法先清除背景后再调用paint方法
update为程序提供了一个钩子来处理由程序触发的不同情形的特殊绘制需求
一般地:
paint理解为组件遭到破坏需要完全重绘
update理解为需在组件追加绘制的情形
对轻量级组件而言,update不会清零背景而是直接调用paint,故二者没啥区别
也就是说轻量级组件是不应该发生追加绘制的情形 -
轻量级组件绘制机制
轻量级组件不涉及本地操作系统的窗口,只是依附于重量级组件之上来进行绘制
故其完全有Java代码实现,当其底层的重量级组件被告知需要重绘,就必须将
此重绘信息转化传递到其之上的轻量级子组件,使它们也跟着重绘,这种传递是
通过java.awt.Container的paint方法来实现的,该方法能通知所有与之关联的
可见的要求重绘的轻量级子组件,所以要扩展继承Container类的容器,覆盖paint
时,要在方法最后确保调用super.paint(g)来保证继承链上的其他子组件也被重绘轻量级与本地操作系统之间通过重量级组件来关联,故系统触发重绘分如下两种情况:
- 所依附的重量级组件初次显示,本地系统发起的系统触发重绘,将直接调用
paint - 轻量级组件框架发起的系统触发请求(如改变大小)将导致调用
update
而该方法默认是转调paint方法,由此更能说明轻量级的update与paint没啥区别
- 所依附的重量级组件初次显示,本地系统发起的系统触发重绘,将直接调用
- 系统触发的重量级组件绘制机制
- 最佳实践
- 组件绘制代码必须只出现在
paint方法里 - 程序最好只通过
repaint来间接调用paint实现重绘 - 复杂组件最好调用带参数版的
repaint来减少不必要的重绘 - 重量级组件的追加绘制需要覆写
update方法,而轻量级组件不支持追加绘制 - 扩展
java.awt.Container并覆写paint方法时,一定要调用super.paint(g)来
确保其容器内的子组件被绘制 - 渲染复杂的组件时,使用clip来缩小重绘区域提高性能
- 组件绘制代码必须只出现在
第十一章 事件处理
略
第十二章 Swing用户界面组件
略
第十三章 部署Java应用程序
Jar文件
-
创建Jar文件
用法: jar {ctxui}[vfmn0PMe] [jar-file] [manifest-file] [entry-point] [-C dir] files ... 选项: -c 创建新档案 -t 列出档案目录 -x 从档案中提取指定的 (或所有) 文件 -u 更新现有档案 -v 在标准输出中生成详细输出 -f 指定档案文件名 -m 包含指定清单文件中的清单信息 -n 创建新档案后执行 Pack200 规范化 -e 为捆绑到可执行 jar 文件的独立应用程序 指定应用程序入口点 -0 仅存储; 不使用任何 ZIP 压缩 -P 保留文件名中的前导 '/' (绝对路径) 和 ".." (父目录) 组件 -M 不创建条目的清单文件 -i 为指定的 jar 文件生成索引信息 -C 更改为指定的目录并包含以下文件 如果任何文件为目录, 则对其进行递归处理。 清单文件名, 档案文件名和入口点名称的指定顺序 与 'm', 'f' 和 'e' 标记的指定顺序相同。 示例 1: 将两个类文件归档到一个名为 classes.jar 的档案中: jar cvf classes.jar Foo.class Bar.class 示例 2: 使用现有的清单文件 'mymanifest' 并 将 foo/ 目录中的所有文件归档到 'classes.jar' 中: jar cvfm classes.jar mymanifest -C foo/ . -
清单文件、可执行Jar文件
详情请查看Oracle官方文档:Java Archive Files -
资源
可以通过类加载器定位类,然后在同一位置查找相关资源URL getResource(String name); InputStream getResourceAsStream(String name);例如:
ResourceTest 类位于resource/目录下,则:URL image = ResourceTest.class.getResource("image/001.jpg");真实路径为:
resource/image/001.jpg
参数改为绝对路径:/image/001.jpg,首个”/”表示类加载器默认位置
所以该图片的image目录是和resource目录同一级别 -
jar文件、包密封
对jar文件、jar文件中某些包进行密封操作,能确保类加载时相同包下的类来自同一jar包-
对jar文件密封:
# 在清单文件的主节加入一行 Sealed: true -
对单独的包进行密封:
# 在清单文件增加一节 Name: org/mypackge Sealed: true参考资料:
Sealing Packages within a JAR File
Java中 Package Sealing 的探秘之旅
-
应用首选项的存储
- 属性映射(Property map)通常用来存储配置信息
- 键/值都是字符串
- 存取至文件很容易
- 可以有二级表保存默认值
构造函数:
Properties()、Properties(defaultProperties)
存取方法:String getProperty(key)、Object setProperty(key, value) - 首选项(Preferences)提供一个位置用作存储中心,区别于Properties有如下特点:
- 尽量利用底层操作系统的存储库来实现统一的配置文件位置,如:Windows注册表
- 配置文件命名规范类似包名,相比Properties减少多应用命名冲突
- 除全局共有的系统树外,每个程序用户分别拥有一棵树,类似Windows注册表
系统树:
Preferences root = Preferences.systemRoot()
用户树:Preferences root = Preferences.userRoot()获取节点可以用节点路径名方式、如路径名与类包名相同还有快捷方式:
Preferences node = root.node("/com/mypackage"); Preferences node = root.userNodeForPackage(obj.getClass()); Preferences node = root.systemNodeForPackage(obj.getClass());为了配置数据的迁移,也设计了XML格式的导入导出方法,详查Preferences API
- 服务加载器
Java SE 6 开始提供了一个加载插件的简单机制,即服务加载器(ServiceLoader)
利用此加载器,可以很轻松的实现可插拔式的应用,例如:-
定义一个服务接口
Cipher -
提供该接口的具体实现类若干个
serviceLoader.impl.CaesarCipher
值得注意,实现类必须包含无参构造器 -
在实现类的Jar包目录
META-INF/services/添加UTF-8编码的文本文件
文件名必须与类全限定名一致,如:serviceLoader.impl.CaesarCipher -
在该文本文件中包含类的全限定名,本例为:
serviceLoader.impl.CaesarCipher -
调用如下静态工厂方法,即可加载服务实现插件:
ServiceLoader.load(Cipher.class)
得到的ServiceLoader实例实现了Iterable接口能拿到迭代器(可能有许多实现类)
遍历即可得到真正的实现类的实例(此处实现是延迟加载,迭代器推进时才加载)
-
-
Java Applet
可以使用appletviewer工具运行applet小程序用法: appletviewer <options> url 其中, <options> 包括: -debug 在 Java 调试器中启动小应用程序查看器 -encoding <encoding> 指定 HTML 文件使用的字符编码 -J<runtime flag> 将参数传递到 java 解释器 -J 选项是非标准选项, 如有更改, 恕不另行通知。 - Java Web Start
一种通过Web发布一个JNLP(Java Network Launch Protocal)的描述文件some.jnlp
从而下载Web服务器上的Web Start应用,并在本地运行该应用的技术
第十四章 并发
线程
进程拥有自己一整套变量,线程则共享数据
线程更轻量级,创建撤销开销更小
中断
-
了解中断前先了解广义上的线程阻塞概念:
线程或进程暂时让出CPU,此时的线程或进程进入阻塞状态 -
对一个线程调用
interrupt方法,将尝试为线程的中断状态(布尔值)置位为true
当线程被阻塞时,调用中断方法将会抛出InterruptedException异常而中断阻塞
在中断状态被置位时,调用sleep方法线程不会休眠而是清除中断状态并抛中断异常 - Thread.interrupted vs threadObj.isInterrupted
前者是静态方法,返回当前线程中断状态的同时还清除中断状态(置位为false)
后者是实例方法,返回当前线程是否被中断而不改变此状态 - 发生中断异常后处理的最佳实践
- 捕获该异常,并在随后的catch块中调用如下代码设置中断状态供调用者检测:
Thread.currentThread().interrupt() - 将方法标记为抛出中断异常,使之也变成可中断的方法
- 捕获该异常,并在随后的catch块中调用如下代码设置中断状态供调用者检测:
线程状态
在Thread类内定义了一个枚举类State用来代表线程的若干状态,值得注意的是
这些状态有别与操作系统底层的线程状态,这些状态是基于JVM上定义的,具体包括:
NEW、RUNNABLE、BLOCKED、WAITING、TIMED_WAITING、TERMINATED
下面来详细说明下各个状态:
-
NEW
表示线程是一个还没调用start方法的初始状态 -
RUNNABLE
表示线程在JVM层级中是可执行的,不表明其在操作系统层级为可执行
可能在等待操作系统相关资源,如:I/O、CPU
也可能其正在运行,因为JLS中没有单独表示一个在运行的状态
在抢占式调动中,调度器采用时间片机制给每个线程一段执行时间
如果时间片用完,操作系统剥夺线程运行权,线程又从运行回到可运行状态 -
BLOCKED
表示线程被阻塞,正在等监视器(Monitor,稍后说明)来进入或重进入
一个同步的方法,一般调用对象的wait方法后为了获取监视器而进入此状态 -
WAITING
表示线程正在等待别的线程的适当操作(如:notify、notifyAll)
一般调用对象的无参的wait、无参的join或LockSupport.park进入此状态 -
TIMED_WAITING
表示线程需等待给定的最大时间来结束当前状态,一般调用线程的sleep、
对象的有参的wait、有参的join、LockSupport的parkUntil及parkNanos方法
进入此状态 -
TERMINATED
表示线程由于以下情况中的一种而终止:- 执行完
run()方法返回后 - 执行
run()方法时抛出了异常
- 执行完
线程属性
-
线程优先级
Java线程有三个优先级整形常量,但优先级的值其实可在最低到最高之间的值:
MIN_PRIORITY值为1
NORM_PRIORITY值为5
MAX_PRIORITY值为10
根据不同的操作系统定义的优先级映射到这三个优先级中,例如:
Windows有7个优先级别,而Oracle在Linux下的JVM中,线程优先级则被忽略 - 守护线程
守护线程唯一的用途是为其他线程提供服务,当虚拟机只有守护线程而无用户线程时
系统直接退出,而不管守护线程是否在运行很重要的任务,因此注意:- 在线程调用
start方法之前才允许调用setDaemon(true)设置守护线程 - 守护线程中产生的线程都是守护线程
- 守护线程不要访问固有资源,如:文件、数据库等,因为有随时发生中断的危险
- 在线程调用
-
未捕获异常处理器
由于run方法不能抛出任何受查异常,而非受查异常又会导致线程终止
非受查异常可在线程死亡之前被传递到一个用于未捕获异常的处理器中
该处理器实现Thread.UncaughtExceptionHandler接口- 调用
Thread.setDefaultUncaughtExceptionHandler方法为所有线程
设置一个默认的处理器 - 调用线程实例方法
setUncaughtExceptionHandler方法可为该实例安装处理器
不安装线程默认处理器时默认处理器为空,但不设置单独线程实例的处理器默认处理器为
ThreadGroup对象,此对象实现了处理器接口,该对象的默认操作为:- 该线程有父线程组,调用父线程组的
uncaughtException方法 - 否则,如果线程默认处理器不为空,调用该处理器
- 否则,如果异常是
ThreadDeath的实例,什么都不做 - 否则,将线程名字及异常轨迹输出到
System.err上
- 调用
同步
Monitor Object设计模式
要了解同步,必须先要了解Monitor Object设计模式,然而Java对这经典的模式进行了语言上的封装,采用类比C++的同步实现能更好的加深对Java同步机制的理解
以下简要概括节选自探索Java同步机制
- 资源获取即初始化(RAII, Resource Acquisition Is Initialization)
-
对C++而言是指在一个对象的构造函数获得资源且在此对象的析构函数中释放资源
其中资源可以为对象、内存、文件句柄等 -
对Java而言对这些资源的释放提供
finalize来处理 但最好把此当做最后一道防线(Effective Java第二版第7条)
尽量使用finally语句块来处理资源的释放工作
-
- 区域锁(Scoped Lock)
当一个线程执行时进入一个区域自动获得一个锁,离开此区域时自动释放该锁- C++区域锁使用了RAII技术,分别在构造器、析构函数中得到、释放 一个对操作系统线程锁的抽象类型LOCK
- Java将此过程做了语言上的封装,使用
synchronized关键字即可实现锁的获取与释放
- 条件变量(Condition Variables)
条件变量可以看做是一个参照,某个线程是否需要被挂起或者唤醒都参考于条件变量
对Java而言,默认已经提供Object类的wait、notify、notifyAll方法,这些方法
已经将条件变量做了很好的封装,并不需要自己实现条件变量类
Monitor Object模式四种类型参与者:
- 监视者对象(Monitor Object),定义接口服务供多线程环境使用
- 同步方法,监视者对象定义,任意时刻只有监视者对象的一个同步方法能够被执行
- 监视锁(Monitor Lock),每个监视者对象拥有一把监视锁
- 监视条件(Monitor Condition),与监视锁共同决定方法是否需要被阻塞或恢复执行
Java中的Monitor Object模式实现如下图:
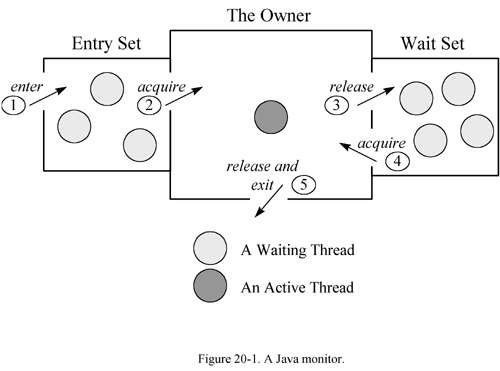
① 调用监视者对象的某个同步方法,等待获取监视锁,此时线程处在等待状态
② 拿到监视锁,线程转为活动线程
③ 某个时刻活动线程调用wait方法释放监视锁,转为等待作态
④ 等待状态的线程某时刻被notify等操作唤醒,取得监视锁,转为活动线程
⑤ 活动线程释放锁并成为终止状态
Java语言通过把Object对象定义为监视者对象,并通过synchronized关键字及notify/notifyAll/wait方法,巧妙的将监视者对象、监视锁、监视条件进行封装隐藏,当然Java也提供显式的锁对象来支持更灵活的控制
参考资料:
探索 Java 同步机制
锁对象(Lock)
Java SE 5.0引入了ReentrantLock类来解决上文提到的由于synchronized自动封装
锁及监视条件导致不灵活的问题,它提供便利的显式锁操作
- 使用锁时就不能用带资源的try语句
- 锁存在于对象上,同一个类的不同对象实例都由属于自身的锁
- 留心临界区代码,由于异常跳出临界区应保证释放锁之前对象不会处于受损状态
- 在构造方法总传入
true时,得到公平策略锁(选取等待时间最长的线程)
条件对象(Condition)
某一线程进入临界区,获取了锁后发现条件不满足它的顺利执行时,必须要在该条件下
进行等待,直到该条件满足要求后方能继续恢复执行,故需条件对象实此效果
- 条件对象命名应该能反映它所表达的条件
等待获得锁与调用条件对象的await不同,后者锁可用时不会立马解除阻塞
它需要等待另一线程调用同一条件上的signalAll才从等待集恢复signalAll仅通知等待线程此时可能满足条件,还需线程再去检测该条件- 当条件有向利于等待线程的方向改变时是调用
signalAll的时机 signalAll仅是解除阻塞,是否被激活还是要去抢占对象锁
synchronized关键字
锁与条件对象的总结如下:
- 锁用来保护代码片段,任何时刻只能有一个线程执行被保护的代码
- 锁可以管理视图进入被保护代码段的线程
- 锁可以拥有一个或多个相关的条件对象
- 每个条件对象管理那些已经进入保护代码段但还不能运行的线程
相较与显式的锁与条件,Java 为每个对象提供一个内部锁,由 synchronized 修饰的方法
将自动被内部锁所保护且内部对象只有一个相关条件
wait方法将线程放到等待集中,notifyAll/notify 方法解除等待线程的阻塞
静态同步方法的内部锁来自于类对象而非实例对象
内部锁与条件的局限性:
-
不能中断正在试图获得锁的线程
-
试图获得锁时不能设定超时时间
-
每个锁仅有单一条件
最佳实践:
- 最好即不使用Lock/Condition也不使用synchronized
尽量选择java.util.concurrent包中的某一种机制 - 如果synchronized关键字适合,尽量使用它减少代码量
- 特别需要Lock/Condition的特性时才使用它
同步阻塞
- 获取锁可以通过:调用同步方法或进入同步代码块
- ad-hoc锁 指某个对象被创建仅仅只是用来使用它所持有的锁
-
客户端锁定 指使用
synchronized代码块截获一个对象的锁来实现额外的原子操作// Vector的set方法是同步的,但分别调用两次非原子操作 Vector<Double> v = new Vector<>(); v.set(1, 3.14); v.set(2, 1.14); // 利用同步块截获该对象,在代码块内达到原子操作 synchronized(v) { v.set(1, 3.14); v.set(2, 1.14); }“服务端”:修改方法都是用了内部锁的对象
“客户端”:利用同步块截获服务端的对象本例来说,本例所在的类为客户端,Vector为服务端,然而Vector并没有承诺
其所有的修改方法都使用了内部锁,故此时客户端锁定的原子性很脆弱
监视器
监视器是以不需人为干预加锁而能保证多线程安全为目的、且面向对象的一种解决方案
监视器概念由 Per Brinch Hansen 和 Tony Hoare 提出,其特征用Java来描述为:
- 监视器类只能包含私有域
- 监视器类的对象有一个相关的锁
- 使用该锁对所有方法进行加锁,确保某刻只有一个线程操作对象的方法修改域
- 该锁可以有任意多个相关条件
然而,Java 的监视器实现却没能完全符合上述特征,
如:允许非私有域、锁条件单一这些都使得线程安全性下降
volatile域
有时仅为了读写一两个实例域使用同步机制开销过大,而不用同步出错概率很大,原因:
- 多处理器计算机能暂时在寄存器或本地内存缓冲区保存内存中的值,使得运行在不同处理器上的线程可能在同一个内存位置取到不同的值
- 编译器可以改变指令执行顺序以使吞吐量最大化,虽不改变代码语义但是编译器的假定前提是认为内存中的值仅可在代码中显示的修改时,然而真实情况内存值是可被另一线程改变
使用同步可以避免以上的问题,详细解释参考如下资料:
JSR-133 Java内存模型和线程规范
Fixing the Java Memory Model
如果向一个变量写入值,而该变量接下来可能被另一个线程读取, 或者从一个变量读值,而该变量可能是之前被另一个线程写入的,此时必须使用同步。
—— Brian Goetz
volatile关键字为实例域的同步访问提供了一种免锁机制,编译器及虚拟机能够知道
被其修饰的域很可能被另一个线程并发更新,故不采取缓存到本地或指令重排
注意:volatile变量不能提供原子性,只单单保证线程间变量可见性
原子性
-
java.util.concurrent.atomic包总有很多实用了高效的机器级指令而非锁来保证操作的原子性,例如:安全的自增、自减 -
大量线程访问相同的原子值会使性能大幅下降,Java SE 8引入了加法器(Adder)及累加器(Accumulator)来解决此问题,利用线程数增加是只是增加多个变量(加数),所有工作完成后才需累加得到最终总和值,其中accumulator将此思路推广到任意的累积操作,如:求最大最小值等满足结合律与交换律的操作
-
CAS、ABA问题
CAS (Compare and Swap),乐观锁,不加锁检测冲突,重试直到成功
与之对应的悲观锁,或称为独占锁,会导致其它需要锁的 线程挂起采用乐观锁会带来ABA问题,问题发生在检测冲突期间,对象被修改后
表面上又骗过冲突检测,而导致的问题,具体分析参考:
死锁
某一时刻,所有线程都被阻塞而无法被唤醒激活,这种状态被称作死锁
导致死锁有如下几种情况:
- 所有线程由于条件不满足都进入阻塞状态
- signalAll方法换为signal,被通知的某个线程条件不满足被阻塞,没任何其他线程可发出通知
线程局部变量
线程局部变量使得变量在各线程间保持隔离独立,其目的不是用来实现多线程下变量共享
相反它为各线程提供各自的实例,避免共享带来的安全及性能隐患(如:实例为非线程
安全而使用同步锁机制带来性能开销)
为了达到变量在各线程间的各自独立而不引入新的竞争条件及同步开销,Java API设计者
提供了很巧妙的解决方法:
- 让
Thread类中包含一个ThreadLocal.ThreadLocalMap包级别的域 - 该Map封装一个
ThreadLocal.ThreadLocalMap.Entry数组 - Entry以弱引用形式将
ThreadLocal实例做为Key,set方法参数值作为Value ThreadLocal的实例由AtomicInteger累加魔数0x61c88647得到hashCode- 计算
hashCode & (Entry[].size-1)得到ThreadLocal实例在Entry数组的索引
每个线程都包含自己的ThreadLocalMap实例,而每个ThreadLocal实例都会以弱引用形式
存于所属线程的Entry的key中,ThreadLocal实例set方法参数值保存在Entry的Value中
Java Doc中关于ThreadLoacl有这样一段描述:
ThreadLocal instances are typically private static fields in classes that wish to associate state with a thread (e.g. a user ID or Transaction ID).
译文:
ThreadLocal实例通常在类中是私有的、静态的域,目的是希望其状态变化保持与线程上下文相关,即线程局部变量的作用域是线程级别(例如:通常一个线程关联一个用户ID或事务ID)
这样规定好处:
- 使用private修饰确保该本地变量设值、取值封装在此类内部进行
使该线程生命周期中对该线程变量的存取有一个统一的入口 - 使用static修饰能够确保在线程的生命周期范围内此线程本地变量的唯一性
拿其他变量类比就更好理解:
| 变量 | 作用范围 | 共享范围 |
|---|---|---|
| 局部变量 | 当前方法内部 | 仅方法内部 |
| 成员变量 | 所有实例方法 | 本实例的成员方法间共享 |
| 静态变量 | 本类 | 本类的所有实例间共享 |
| 线程局部变量 | 本线程 | 本线程的所有类 |
① 假设在一个线程中,存在这种调用关系:A类方法 -> B类方法 -> C类方法
② D类里有一个非私有、非静态的线程本地变量:ThreadLocal<Float> f
③ B类、C类各自都包含一个D类的成员域:D d = new D()
此时线程的ThreadLocalMap中的大致如下图所示:
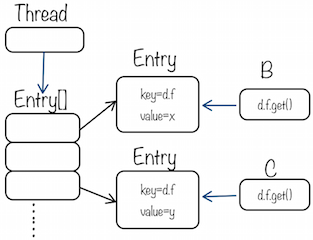
在线程的Map中存在ThreadLocal<Float>的两个不同实例:一个在B类,一个在C类
语法上是完全被允许的,但在B、C类分别调用d.f.get()却得到不同的值,x或y
违背了同一线程作用范围内,相同线程本地变量名所引用的实例应该唯一确定的
然而将②改为静态本地变量时,线程的ThreadLocalMap中的大致如下图所示:
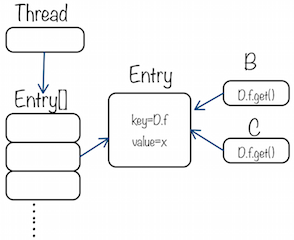
此时不光B、C,整个线程上下文中任意位置调用D.f.get()都是的到相同对象的相同值
最佳实践:
- 尽量使用private static修饰线程本地变量,保证其线程级变量的概念定义
- 采用线程池技术时,一次线程作业任务完成时主动调它的
remove()归置线程状态
参考资料:
Why 0x61c88647
ThreadLocal 和神奇的 0x61c88647
聊一聊ThreadLocal 内存泄漏
并发编程 | ThreadLocal源码深入分析
将ThreadLocal变量设置为private static的好处是啥?tinylcy的回答
ThreadLocal为什么要加static修饰符
另一个角度理解java的ThreadLocal
锁测试与超时
Java SE 5.0 提供了一个基于 FIFO 等待队列实现的同步器基础框架
称作AQS(Abstract Queued Synchronizer)
它是JUC中所有锁、多线程并发及线程同步器等组件的基石
原理介绍参考:扒一扒ReentrantLock以及AQS实现原理
lock方法不能被中断,如果等待获取锁时被中断,那该中断线程在获取锁时一直处于
阻塞状态,万一发生死锁,lock方法将无法终止,为防止此问题故设计出可中断的测试锁
Lock方法:
- tryLock尝试抢夺锁(即使有公平锁策略),得到返回true失败立刻返回false
- tryLock(long, TimeUnit) 尝试获得锁,阻塞不超过给定值,成功返回true
- lockInterruptibly尝试获得锁,超时时间无限制,阻塞时间不确定,中断抛异常
Condition方法:
- await(long, TimeUnit)进入条件等待集,要么超时要么移出等待集否则阻塞
- awaitUninterruptibly()进入条件等待集,除非从集中移出否则一直阻塞即使被中断
读写锁
与ReentrantLock不同,ReentrantReadWriteLock它的读锁可被读操作共用
而写锁排斥所有的读写操作,调用readLock()、writeLock()分别获得读写锁
弃用stop和suspend
-
stop
使线程抛出ThreadDeath异常、立刻释放持有的对象的锁
原本受锁保护的对象的状态可能遭到破坏,造成对象状态不一致问题 -
suspend
挂起线程时不释放该线程所持有的对象的锁,如果使线程挂起的那个线程
请求被挂起的线程锁持有的锁时,互相等待而导致死锁
阻塞队列
实际编程要尽可能远离Java并发底层结构,使用高层次的并发结构更方便、安全
许多线程问题,可以使用队列优雅安全的方式形式化,而这种队列称为阻塞队列
较普通队列而言,它拥有如下特性:
- 向已满队列添加元素时,当前线程会被阻塞
- 向空队列移出一个元素时,当前线程也会被阻塞
阻塞队列接口java.util.concurrent.BlockingQueue<E>包含的方法按照处理方式不同可归为:
| 方法\反馈 | 抛出异常 | 特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() | take() | poll(time,unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
- 抛出异常: 向满队列添加、空队列移除,直接抛出异常
- 特殊值: 向满队列添加、空队列移除或查看,分别返回false、null
- 阻塞: 向满队列添加、空队列移除,阻塞直到满足操作要求
- 超时: 在返回特殊值之上添加时间限制,超时同样返回false、null
Java SE 7之后提供了7个具体的实现类:
- ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue :一个由链表结构组成的
有界注 阻塞队列。 - PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
注意:
- LinkedBlockingQueue此书说其无上限,其实默认上限
Integer.MAX_VALUE - ArrayBlockingQueue有界,需指定容量,还可传入可选参数来指定是否使用公平性
- PriorityBlockingQueue优先级队列,默认自然排序而非先进先出,可自定义比较器。
- 队列满时,put 方法不阻塞、offer 方法返回true,都可以正常放入队列
- 超过队列大小的元素虽然也可以放入,但不参与排序
- DelayQueue实现Delayed接口,其getDelay方法返回剩余延迟,负数即延迟结束才能移除
- LinkedTransferQueue实现TransferQueue接口,其transfer方法阻塞直到有另一线程将元素删除
- SynchronousQueue 由于不存元素,offer 永远false put/take 阻塞,需其他线程调用take/put
具体实现细节可参考:
聊聊并发(七)——Java中的阻塞队列
Java Doc
线程安全的集合
多线程程序中并发修改非线程安全的集合结果是灾难性的,故需使用线程安全集合
早期的同步包装器可使非线程安全的集合变为线程安全,但其并发性能一般
为了提高并发性能,JUC (java.util.concurrent)包提供了高效的并发集合
- 高效的映射、集和队列
-
ConcurrentHashMap
与同步集合不同,它细化锁的粒度来提高并发性(锁bucket)
此外其提供newKeySet静态方法返回一个并发的集视图
实例方法keySet可生产当前映射的键集,能删改不能加
Java SE 8 新添加带默认参数的keySet就可添加集,默认值为所传值
不允许Key和value为null
Java SE 8 将桶大小超过8之后,链表将组织为树结构,如果键类型实现了Comparable 将使用比较的顺序来处理 hash 冲突问题,前提是equeals与比较的次序 要有一致性,否则有不可预料的错误,如下面链接所述问题:
HashMaps with Comparable keys not working as expected
关于 Java SE 8 中HashMap的结构,请参考:
Java8系列之重新认识HashMap -
ConcurrentSkipListMap、ConcurrentSkipListSet
此结构的Set是包装了同结构的值为Boolean.TRUE的Map类
而SkipList(跳表)数据结构算法较树型平衡结构既简单也高效 -
ConcurrentLinkedQueue
无边界线程安全队列,与阻塞队列不同,队列为空pull方法将返回空
-
- 映射条目的原子更新
putIfAbsent(key, newValue)
不存在增加此key、newValue,否则返回key对于的原valuecomputeIfAbsent(key, Function)
效果同上,只不过newValue是通过Function计算得来的computeIfPresent(key, Function)与上面相反,存在key时才把原value替换为Function计算得来的merge(key, default, BiFunction)
不存在时,增加key、defalut值,否则将原值参与BiFunction计算得出
- 对并发散列映射的批操作
Java SE 8为并发散列映射提供了3种批操作:- search 搜索
- reduce 归约
- forEach 逐一
这3种操作每种又有4个版本(operation替换为具体操作名):
- operationKeys 处理键
- operationValues 处理值
- operation 处理键值
- operationEntries 处理Map.Entry
具体方法声明格式:
U operationXXX(long, BiFunction)
其中long为并行阈值,如果Map中元素多于此值就会并行完成操作
后面的函数即是具体操作除此之外,
forEach还有另一种转换器形式,转换结果为null时自动剔除:
forEach(long, Function, BiFunction, Consumer)
中间的BiFunction函数起过滤及转换作用 -
写时拷贝数组
CopyOnWriteArrayList和CopyOnWriteArraySet为线程安全集合
所有修改线程对底层数组进行复制,故迭代过程中有可能旧数组已过时 - 并行数组算法
Java SE 8中Arrays提供了大量并行化操作:- parallelSort
并行的对所给数组进行排序,重载的方法包含自定义比较器、范围内排序
并行阈值MIN_ARRAY_SORT_GRAN = 1 << 13
即:数组长度大于8192才进行并行排序处理,并行使用ForkJoin框架 - parallelSetAll
将数组元素的值初始化为所给定的与数组索引相关的函数的计算结果 - parallelPrefix
从数组索引为1的元素开始,将索引处的值修改为给定函数的计算结果值
该函数有两个参数,分别为前一索引处的值与当前索引处的值
- parallelSort
- 较早的线程安全集合
Java初始版本中,Vector与Hashtable提供了线程安全的动态数组与散列表
现在两个类被废弃,取而代之的是非线程安全的ArrayList与HashMap Collections.synchronizedXXX是提供线程安全转换的包装器工厂方法
使用同步包装器可以将此非线程安全的类转为线程安全但要注意:- 确保没有线程使用原始类型的非同步方法(匿名传递原始类型给包装器)
- 在另一线程使用迭代器修改集合,需要使用客户端锁定(§14.5.4)
迭代时,其他线程修改了集合时当前线程会立刻抛出并发修改异常
综上所述,多线程中最好使用JUC并发包定义的集合来替代同步包装器
参考资料:
JAVA并发编程J.U.C学习总结
Callable与Future
-
Callable
Runnable封装异步运行任务,Callable与之相似,但有返回值
返回值类型与参数化类型一致 - Future
保存异步计算结果,需要时调用方法获得结果- get() 有结果立即返回,无结果阻塞直到计算完成,中断抛异常
- get(long, TimeUnit) 和前面一样,多出超时时抛超时异常
- isDone() 正在进行返回false,完成返回true
- cancel(boolean) 没开始就取消不执行,计算中booean为true就中断
- FutureTask
实现Callable与Future接口的包装器,将Callable转为Future和Runnable
执行器
构建一个线程是有一定开销的,维护一个线程池能减少一定开销及并发线程数
执行器(Executors)类有许多静态工厂来构建线程池:
| 方法 | 描述 |
|---|---|
| newCachedThreadPool | 必要时创建新线程,空闲线程保留60秒 |
| newFixedThreadPool | 含固定数量线程,空闲线程一直保留 |
| newSingleThreadExecutor | 只含单一线程,顺序执行提交的任务 |
| newScheduledThreadPool | 用于预定执行的固定线程池,替代java.util.Timer |
| newSingleThreadScheduledExecutor | 用于预定执行的单线程池 |
前三方法返回实现了ExecutorService接口的ThreadPoolExecutor
后两方法返回实现了ScheduledExecutorService接口的ScheduledThreadPoolExecutor
ExcecutorService
-
Future<?> submit(Runnable)
Future的get方法返回null -
Future
submit(Runnable, T) Future的get方法返回给定的T对象 -
Future
submit(Calllable ) Future的get方法返回Callable的计算结果 -
当线程池用完时,可调用如下方法启动线程池关闭序列:
shutdown:不再接受新任务、所有任务完毕后池中线程死亡
shutdownNow:取消未开始的所有任务、试图中断正在执行的线程 -
使用线程池最佳实践:
- 调用Executors的静态方法获取线程池
- 调用submit提交Runnable或Callable
- 如果取消一个任务或提交一个Callable对象,要保存好Future对象
- 不在提交任务时,调用shutdown
ScheduledExecutorService
此接口为预定执行、重复执行的任务而设计
可以理解为允许使用线程池的java.util.Time的泛化
-
ScheduledFuture
schedule(Callable, long, TimeUnit) 指定的时间之后执行Callable -
ScheduledFuture<?> schedule(Runnable, long, TimeUnit) 指定的时间之后执行Runnable
-
ScheduledFuture<?> scheduleAtFixedRate(Runnable, long, long, TimeUnit)
在初始的延迟(第一个long)结束后,每隔一个周期(第二个long)
执行一次Runnable,不管上一个任务是否已完成 -
ScheduledFuture<?> scheduleWithFixedDelay(Runnable, long, long, TimeUnit)
在初始的延迟(第一个long)结束后,运行任务
之后都是在上一任务结束后延迟(第二个long)的长度执行下一任务
ExecutorService 控制任务组
执行器服务不单可作为线程池使用,换个角度看如果在池中的任务为一组
相关任务时,执行器还能担当控制者的角色,具体控制操作包含:
-
shutdownNow 立刻取消任务组
-
T invokeAny(Collection<Callable<T>>)
返回任务集合中任意一个已完成的结果,无法知道具体是哪个任务
此方法还有重载方法,加入超时时间,超时抛出超时异常 -
List<Future<T>> invokeAll(Collection<Callable<T>>)
得到所有任务的Future,任务与结果对应,遍历Future可能阻塞等待
此方法还有重载方法,加入超时时间,超时抛出超时异常 有时可能不需知道任务与结果的对应关系,而想按结果生成顺序获取
这就要将当前执行器包装为ExecutorCompletionService -
ExecutorCompletionService
构造方法接收一个执行器对象,然后可以向其submit任务
获取任务执行结果Future时,有已下几个方式:- take()
移出并返回已完成Future队列中一个,还无已完成时阻塞 - poll()
移出并返回已完成Future队列中一个,还无已完成时返回null
此方法有加入超时时间的重载版本,等待一定时间后再返回
- take()
参考资料:
深入分析java线程池的实现原理
Fork-Join框架
学会使用该框架时,以下4个类是必须了解:
-
ForkJoinPool 所有fork-join任务被执行的线程池
一般此为全局唯一故常声明为静态,由以下几种获取方式// Java SE 6或7 static fjPool = new ForkJoinPool(); // Java SE 8及之后 ForkJoinPool.commonPool();让该线程池执行任务的方法可以参考如下表格:
—— 非fork/join框架的调用 fork/join框架的调用 安排异步执行 execute(ForkJoinTask) ForkJoinTask.fork() 等待获取结果 invoke(ForkJoinTask) ForkJoinTask.invoke() 安排执行及获得Future submit(ForkJoinTask) ForkJoinTask.fork() (ForkJoinTask实现Future) - RecursiveTask< T > 其子类为有返回值的fork-join任务
- RecursiveAction 和RecursiveTask类似只是没返回值
- ForkJoinTask< V > 上两个类的父类,fork、join方法在其中定义
- fork()
在框架池中执行此任务 - join()
计算结束获取结果 - static invokeAll(ForkJoinTask<?>… tasks)
批量fork所给的任务
TIPS:
- 将一个任务分为两个子任务,分别调用子任务的fork效率没有一个调用fork另一直接调用compute高
- 调用join要在最后调用,否则可能产生不了并行计算效果
- 不应该直接调用ForkJoinPool的invoke方法,应该调用Recursive[Task/Action]的fork或compute
- 鉴于并行计算抛出非检查异常跟着调用栈相对复杂,最好在调用compute的方法中捕获并打印异常栈
- 不盲目追求并行计算,选择不当可能并行计算反倒没有串行处理效率高
- fork()
参考资料:
A Java Fork/Join Framework by Doug Lea
Beginner’s Introduction to Java’s ForkJoin Framework
深入浅出java7中的Fork/Join框架
可完成Future
Java SE 5时引入了Future对象来异步计算结果,但阻塞或轮询的结果获取方式不尽如人意
因此Google的Guava引入了增强型的ListenableFuture来增强Future的功能
Java SE 8引入了CompletableFuture来对Future做进一步的扩展来简化异步编程的复杂性
CompletableFuture类实现CompletionStage和Future接口,保留原Future的用法
增加的join方法与get方法类,但无声明异常,而是将异常封装到非检查异常
- CompletableFuture(下文将简称为CF)的创建
-
new创建
// 未与任何任务关联,此时get方法将会一直阻塞,使用主动完成可恢复 CompletableFuture<Integer> cf = new CompletableFuture<>(); // CF的正常主动完成,get将得到所给的100 cf.complete(100); // CF的异常主动完成,get将抛所给异常 cf.completeExceptionally(new Exception()); // 主动完成只能被调用一次,但下面两方法将强制修改后续get方法的值或异常 cf.obtrudeValue(200); cf.obtrudeException(new Exception()); -
静态工厂创建
// 返回给定结果的CF对象 CompletableFuture.completedFuture(value) // 以下四个静态指定异步任务创建CF对象 // 任务为Runnable故无返回值 static CompletableFuture<Void> runAsync(Runnable) static CompletableFuture<Void> runAsync(Runnable, Executor) // Supplier函数式接口提供返回值 static <U> CompletableFuture<U> supplyAsync(Supplier<U>) static <U> CompletableFuture<U> supplyAsync(Supplier<U>, Executor)注: 以Async结尾没指定Executor的方法使用ForkJoinPool.commonPool()
作为异步代码执行的线程池,否则使用指定执行器,下面方法类似
-
-
任务完成时进行其他任务后返回原CF的结果
当CF的计算结果完成、或抛异常时,执行特定的Action,方法有:// 这些方法都返回新的CF对象,但该对象的结果是原始CF的计算结果 whenComplete(BiConsumer<? super T,? super Throwable>) whenCompleteAsync(BiConsumer<? super T,? super Throwable>) whenCompleteAsync(BiConsumer<? super T,? super Throwable>, Executor) exceptionally(Function<Throwable,? extends T>)注:Async后缀的方法在线程池一样时,后面Action不一定和前任务在同一线程
但无Async后缀的一定和前任务在同一线程例子:
// 耗时计算,为精简省略具体代码 public static void longTimeCompute() {} /* * 为了清晰显示每一次调用过程,采取了分步骤操作 * 其实完全可以组合匿名方法调用链接,例如: * CompletableFuture.supply(foo).whenComplete(bar) */ public static void main(String[] args) { // 原始CF CompletableFuture<Integer> cf = CompletableFuture.supplyAsync(() -> { longTimeCompute(); return 0; }); // 原始CF完成后的其他Action CompletableFuture<Integer> fu = cf.whenCompleteAsync((n, t) -> { try { // 为了线程图能分隔原始CF和后续Action Thread.sleep(2000); } catch (Exception e) { e.printStackTrace(); } longTimeCompute(); }); // 此处仅为验证join或get的阻塞 和 Action返回值是原CF的结果 System.out.println(fu.join()); longTimeCompute(); }Java VisualVM 运行线程图:
worker-1线程休眠[紫]的两侧运行[绿]分别为原始CF、后续Action
main线程调用join,一直驻留[橙]等结果,Action结束才开运行[绿]
虽然用Async的方法,但Action可能跟原始CF同一线程,且结束后竟然被终结

“Java VisualVM 线程状态图”与“线程状态”对应关系:
-
运行:
调用线程的
start()方法后,线程处于 RUNNABLE -
休眠:
调用线程静态方法
Thread.sleep(long n)后,线程处于 TIMED_WAITING (sleeping) -
等待:
- 调用
object.wait()、thread.join()后, 线程处于 WAITING (on object monitor) - 调用
object.wait(long)、thread.join(long)后, 线程处于 TIMED_WAITING (on object monitor)
- 调用
-
驻留:
- 调用
LockSupport.park()后,线程处于 WAITING (parking) - 调用 LockSupport 的
parkUntil(long)、parkNanos(long)后,线程处于 TIMED_WAITING (parking)
注意:使用 JDK8 的附带的 jvisualvm 去监视 JDK11 的应用时,WATTING/TIMED_WATING (parking) 显示的状态是等待而非驻留(明显是错误的)。在 JDK9 及以上版本中,已经不附带 jvisualvm 工具,请移步这里下载,目前已支持 JDK12,使用新版本就能解决 parking 时状态显示错误的问题。
- 调用
-
监视:
线程申请监视器锁却不可得时被阻塞时,线程处于 BLOCKED (on object monitor)
-
-
任务完成时对结果进行转换任务后返回新CF的结果
相较于前一节,最后返回的结果为新CF的结果类型,原CF值只作为数据输入/* 下面三个方法都返回CompletableFuture<U>,能处理原FC异常 * BiFunction 接受原CF的结果T 和 原CF抛出的异常 * 返回新结果U * T 和 U 类型可以不同,故被称做转换 T -> U */ handle(BiFunction<? super T,Throwable, ? extends U>) handleAsync(BiFunction<? super T,Throwable,? extends U>) handleAsync(BiFunction<? super T,Throwable,? extends U>, Executor) /* 下面三个方法都返回CompletableFuture<U>,不能处理原FC异常 * BiFunction 接受原CF的结果T 和 原CF抛出的异常 * 返回新结果U * T 和 U 类型可以不同,故被称做转换 T -> U */ thenApply(Function<? super T,? extends U>) thenApplyAsync(Function<? super T,? extends U>) thenApplyAsync(Function<? super T,? extends U>, Executor)例子:
public static void main(String[] args) { CompletableFuture<String> cf = CompletableFuture.supplyAsync(() -> { return Arrays.asList("Tom", "Scott", "Ryan"); }).thenApply((names) -> { StringJoiner sj = new StringJoiner(", "); for (Object name : names) { sj.add((String) name); } return sj.toString(); }).whenComplete((str, e) -> { System.out.println(str + " are best friends!"); }); /* 为演示阻塞主线程,否则异步线程未执行程序就结束 * 其次验证thenApply方法的转换结果特性:将List转为String * 该结果由thenComplete(验证此方法的传递结果特性)生成的CF返回 */ System.out.println(cf.get()); } // 打印结果: // Tom, Scott, Ryan are best friends! // Tom, Scott, Ryan -
任务完成时对结果进行操作后返回无结果的新CF
这类型的方法只对原任务的结果进行处理但无返回或返回null(纯消费无产出)下面几个方法属于此类型:
// 由于无返回计算中故方法返回CompletableFuture<Void> thenAccept(Consumer<? super T>) thenAcceptAsync(Consumer<? super T>) thenAcceptAsync(Consumer<? super T>, Executor)例子:
public static void main(String[] args) { CompletableFuture<String> cf = CompletableFuture.supplyAsync(() -> { return Arrays.asList("Tom", "Scott", "Ryan"); }).thenApply((names) -> { StringJoiner sj = new StringJoiner(", "); for (Object name : names) { sj.add((String) name); } return sj.toString(); }).thenAccept((str) -> { System.out.println(str + " are best friends!"); }); /* 为演示阻塞主线程,否则异步线程未执行程序就结束 * 其次验证thenAccept方法的纯消费特性:消费String返回null */ System.out.println(cf.get()); } // 打印结果: // Tom, Scott, Ryan are best friends! // null上述三方法纯消费一个CF结果,下面四个方法则同时消费两个CF的结果:
// 这些方法也同样返回 CompletableFuture<Void> thenAcceptBoth(CompletionStage<? extends U>, BiConsumer<? super T,? super U>) thenAcceptBothAsync(CompletionStage<? extends U>, BiConsumer<? super T,? super U>) thenAcceptBothAsync(CompletionStage<? extends U>, BiConsumer<? super T,? super U>, Executor) runAfterBoth(CompletionStage<?>, Runnable)例子:
public static void main(String[] args) { CompletableFuture<Integer> cf1 = CompletableFuture.supplyAsync(() -> { longTimeCompute(); return 1; }); CompletableFuture<Void> cf2 = CompletableFuture.supplyAsync(() -> { longTimeCompute(); return 2; }).thenAcceptBoth(cf1, (x, y) -> { try { // 为了在线程图中区分不同CF任务 Thread.sleep(2000); } catch (Exception e) { e.printStackTrace(); } longTimeCompute(); System.out.println("1+2=" + (x + y)); }); /* 为演示阻塞主线程,否则异步线程未执行程序就结束 * 其次验证thenAcceptBoth方法的纯消费特性:消费1、2返回null */ System.out.println(cf2.get()); }运行线程图:
worker-1和worker-2线程分别运行cf1、cf2的任务,且为并发抢占资源
因为worker-1线程运行[绿]时worker-2线程处于监视[粉]状态,反之亦然
cf1、cf2完毕后,worker-1线程休眠[紫]后执行再 thenAcceptBoth 的任务
main线程调用 get,一直驻留[橙]等结果
还有一组方法压根不消费原CF的结果,只是单纯执行任务:
// 由于不返回计算结果故方法都返回CompletableFuture<Void>类型的对象 thenRun(Runnable) thenRunAsync(Runnable) thenRunAsync(Runnable, Executor executor)根据方法的参数类型能了解该方法大致属于何种类型,一般地:
- Runnable参数:此方法忽略原CF的计算结果
- Consumer参数:纯消费原CF计算结果
- BiConsumer参数:会同时消费两个CF的计算结果
- Function参数:会对原CF的计算结果做转换
- BiFunction参数:会同时对两个CF的计算结果做转换
-
任务与任务组合成复合任务
通俗讲即为 cf1 + cf2 -> cf3当cf2依赖cf1的计算结果时,可调用下面这组方法:
// 方法都返回CompletableFuture<U>对象 thenCompose(Function<? super T,? extends CompletionStage<U>>) thenComposeAsync(Function<? super T,? extends CompletionStage<U>>) thenComposeAsync(Function<? super T,? extends CompletionStage<U>>, Executor)当cf1、cf2独立可并行执行时,可调用下面这组方法:
// 方法都返回CompletableFuture<U>对象 thenCombine(CompletionStage<? extends U>, BiFunction<? super T,? super U,? extends V>) thenCombineAsync(CompletionStage<? extends U>, BiFunction<? super T,? super U,? extends V>) thenCombineAsync(CompletionStage<? extends U>, BiFunction<? super T,? super U,? extends V>, Executor)例子:
// 任务cf1 CompletableFuture<Integer> cf1 = CompletableFuture.supplyAsync(() -> { // 耗时计算 // longTimeCompute(); return 1; }); // 组合任务cf3 CompletableFuture<Integer> cf3 = cf1.thenCompose((n) -> { // 任务cf2 CompletableFuture<Integer> cf2 = CompletableFuture.supplyAsync(() -> { return n + 2; }); // thenCompose方法内部返回对象:cf2 cf2.thenRun(()->{System.out.println("cf2 = " + cf2);}); return cf2; }); // thenCompose方法外部返回对象:cf3 System.out.println("cf3 = " + cf3); System.out.println("cf3返回值:" + cf3.get());注意:
thenCompose的返回对象不一定是方法中Function参数的返回对象
取决于被组合的任务是否已经有计算结果,当且仅当:
(cf1完成) && (cf2完成) -> cf2=cf3当注释掉cf1的耗时计算,由于cf1、cf2任务执行快速
cf3就是thenCompose方法的函数式参数Function的返回值,结果如下:cf2 = java.util.concurrent.CompletableFuture@4eec7777[Completed normally] cf3 = java.util.concurrent.CompletableFuture@4eec7777[Completed normally] cf3返回值:3 注意cf2的状态:Completed normally然而,cf1执行耗时计算,cf3就不是函数式参数的返回值,结果如下:
cf3 = java.util.concurrent.CompletableFuture@7229724f[Not completed] cf2 = java.util.concurrent.CompletableFuture@c4d7416[Completed normally] cf3返回值:3 注意cf2的状态:Not completed -
Either
与thenAcceptBoth、runAfterBoth不同,下面介绍的方法只要任意一个CF
计算完成的时候,就会执行一个操作,操作可以是消费方法、转换方法:// 任意一个有结果,执行消费方法,返回CompletableFuture<Void> acceptEither(CompletionStage<? extends T>, Consumer<? super T>) acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T>) acceptEitherAsync(CompletionStage<? extends T> other, Consumer<? super T>, Executor) // 任意一个有结果,执行转换方法,返回CompletableFuture<U> applyToEither(CompletionStage<? extends T>, Function<? super T,U>) applyToEitherAsync(CompletionStage<? extends T>, Function<? super T,U>) applyToEitherAsync(CompletionStage<? extends T>, Function<? super T,U>, Executor)假设:A.acceptEither(B, consumer)
这个调用能被正确调用的前提:B 的结果类型 extends A 的结果类型例子:
CompletableFuture<Integer> cf = CompletableFuture.supplyAsync(() -> { longTimeCompute(); return 1; }).applyToEither(CompletableFuture.supplyAsync(() -> { longTimeCompute(); return 2; }), (x) -> { return x; }); longTimeCompute(); System.out.println("cf返回值:" + cf.get()); -
allOf、anyOf
API中还提供了几个用来组合多个CF的静态方法:// 所有CF都执行完,不好组合各个CF的计算结果,故返回Void的结果 static CompletableFuture<Void> allOf(CompletableFuture<?>...) // 任意一个CF完成,无法确认是哪个CF的计算结果,故返回Object的结果 static CompletableFuture<Object> anyOf(CompletableFuture<?>...)Guava中解决了allOf方法无法返回包含所有CF计算结果的问题,具体方法:
// 返回ListenableFuture<List<V>>,要求所有CF返回结果要有共同的父类 Futures.allAsList(ListenableFuture<? extends V>...)
同步器
J.U.C包含了几个帮助人们管理相互合作的线程即的类,它们是:
| 类 | 类的功能 | 说明 |
|---|---|---|
| CyclicBarrier | 允许线程集等待直至其中预定目的线程到达一个公共栅栏,然后可以选择一个处理栅栏的动作 | 当大量的线程需要在它们的结果可用之前完成时 |
| Phaser | 类似循环栅栏,不过有一个可变的计数 | Java SE 7引入 |
| CountDownLatch | 允许线程集等待直到计数器为0 | 一个或多个线程需要等待直到指定数目的事件发生 |
| Exchanger | 允许两个线程在要交换的对象准备好时交换对象 | 当两线程工作在同一数据结构的两个实例上的时候,一个向实例添加数据而一个从实例清除数据 |
| Semaphore | 允许线程集等待直到被允许继续运行为止 | 限制访问资源的线程总数,如果许可数是1,常常阻塞线程直到另一个线程给出许可为止 |
| SynchronousQueue | 允许一个线程把对象交给另一个线程 | 在没有显式同步的情况下,当两个线程准备好将一个对象从一个线程传递到另一个时 |
-
信号量
信号量对象维护一个计数,线程通过acquire请求许可,而许可数目是固定的
用此来控制线程数量,拥有许可的线程通过release释放许可使用场景:一般用来控制访问某资源的线程总数
-
倒计时门栓
让线程集等待直到门栓对象的计数变为0,门栓是一次性的,计数为0就不能重用了
某线程完成某事件时调用countDown来减少等待的事件个数使用场景:线程继续执行依赖其他线程完成某个事件的场景
-
栅栏
为线程集提供一个集结点,所有线程到达集结点时才开始接下来的操作
线程到达集结点时调用await方法等待,由栅栏对象负责统计线程数
达到设置好的线程数时,等待自动恢复,可以指定栅栏撤销时的Runnable
相比较倒计时门栓,栅栏是可重用的,而Phaser可根据阶段不同指定不同线程数
栅栏却只能固定的线程数使用场景:累计到达集结的的线程到达一个确定数目时,这些线程才能继续执行
-
交换器
一个线程向同数据结构的不同实例增加数据,另一在不同实例减少数据时 只需互相交换实例,即可完成任务使用场景:两个线程用同一个数据缓冲区的两个不同实例时,就可以使用交换器
-
同步队列
队列本身不含任何元素,一个线程put数据到队列时阻塞,直到另一线程take数据
才解除阻塞使用场景:不允许任务堆积且生产者、消费者要严格配对时使用





