![]()
序
本 Java 技术栈笔记系列文章,是读《JavaGuide(Java学习&面试指南)》这篇涵盖 Java 程序员需要掌握的核心知识的文章时的个人的摘录及补充笔记。未读此篇指南的读者请优先阅读,而本笔记仅针对个人情况做了筛选摘录与补充,留以自用,若同时也能您有所帮助深感荣幸。
在此感谢 JavaGuide 及开源社区,对本文有何建议欢迎补充。
JVM
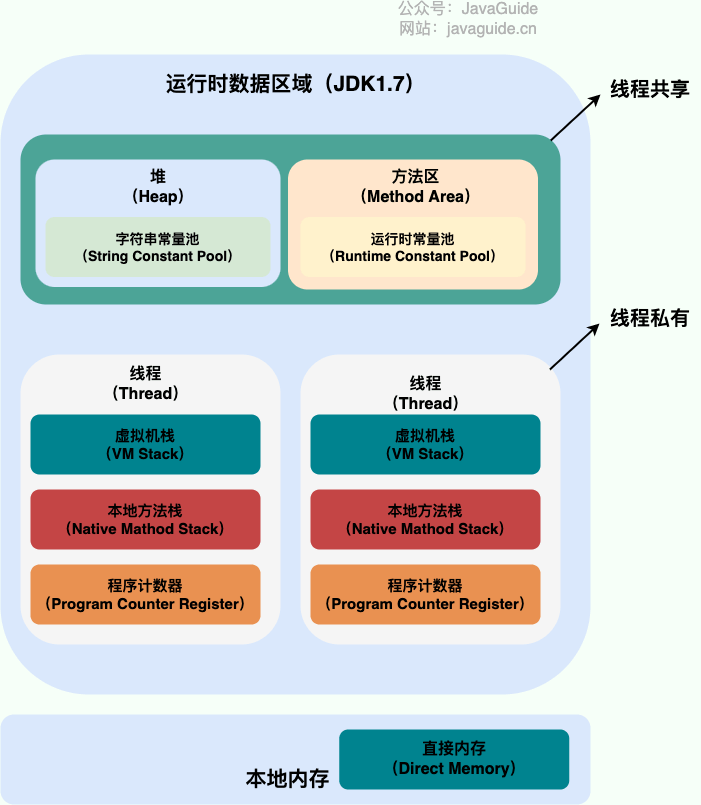
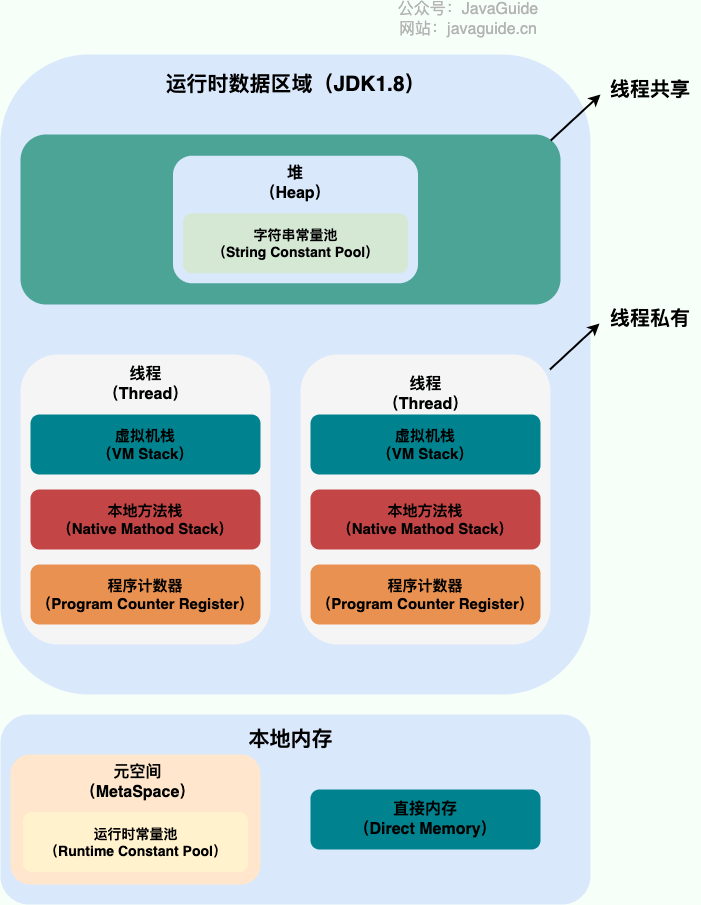
Java 内存区域
Java 虚拟机从 8 版本后对内存区域做了一些调整,故将分析版本 7 与版本 8 来做对比。
-
JDK 7
-
JDK 8
-
线程私有部分
-
程序计数器
- 当前线程所执行字节码的行号指示器,解析器工作是改变此计数器值来选取下一条待执行的字节码
- 程序的分支、循环、跳转、异常处理、线程恢复等都需依赖此计数器来实现
- 线程切换后能恢复到之前的执行位置,也需要依托此线程私有的线程计数器实现
- 随线程创建而创建,随线程结束而删除
- 该区域是唯一不会出现
OutOfMemoryError的内存区域
-
虚拟机栈
-
每个线程都私有的栈数据结构的区域,用来实现线程中 Java 非本地方法的调用
-
每一次方法调用会产生一个栈帧的入栈操作,方法执行结束对应一个栈帧的出栈操作
-
每个栈帧包含:
-
局部变量表
-
存放编译期可知的各种数据类型:基本类型、对象引用以及 returnAddress 类型的变量
returnAddress 类型指向当前字节码中包含
jsr、jsr_w、ret指令的位置的地址,这些指令用来实现方法中调用其它方法时,将当前方法程序计数器的值压入占中,然后转移执行子方法JDK 1.7 之后不在使用这种方式进行子方法调用,取而代之使用invokedynamic指令 -
32 位以内的数据类型占用一个 Slot (含引用类型、ReturnAddress)
-
64 位的类型(long、double)占两个 Slot
-
-
操作数栈
- 存放方法执行过程中产生的中间计算结果及计算过程中产生的临时变量
-
动态链接
- 主要服务一个方法需要调用其他方法的场景,它讲常量池中指向方法的符号引用转化为内存的直接引用,此过程被称作动态链接
-
方法返回地址
- 用来存储当前方法调用子方法的指令的下一条指令地址。
- 当发生子方法调用时,当前方法的栈帧被压入栈,并且包含了该方法返回地址
- 子方法执行完毕后,程序控制会回到这个地址指定的指令,继续执行
-
-
虚拟机栈空间有限,如果函数调用陷入无限循环大量栈帧的压入,栈结构过深超出最大深度的时候
就会抛出
StackOverFlowError错误。如果栈的内存大小可动态扩展,如果虚拟机动态扩展时无法申请到足够空间的内存时,会抛出OutOfMemoryError错误。HotSpot 虚拟机栈容量不可以动态扩展,不会因为动态扩展导致 OOM,
但是,如果线程一开始申请时就空间不够,仍然会导致 OOM。
-
-
本地方法栈
- 与虚拟机栈作用类似,区别是该栈执行的是本地方法(native 关键字修饰的方法)
- HotSpot 虚拟机中,虚拟机栈与本地方法栈合二为一,共享同一个栈空间
- 该空间同样可能抛出
StackOverFlowError、OutOfMemoryError错误
-
-
线程共享部分
-
堆
-
JVM 启动时创建的一块所有线程共享的最大块内存区域,目的是存储对象实例及数组
-
Java 世界 “几乎” 所有对象都在堆中分配,但 JIT 编译器出于优化目的也会在栈上分配
-
逃逸分析用于确定对象的作用域是否逃逸除了当前方法或线程的范围。
如没有逃逸,那么编译器可以进行栈上分配。
-
标量替换用于将对象拆分成它们的各个字段(标量)并将这些标量分配都栈上,
而不是作为整个对象分配到堆上。
-
逃逸分析及标量替换一般会一起使用,当对象被证实没有逃逸,编译器就进行标量替换
对象进行标量替换时,其字段若为引用类型时,该引用指向的对象仍然在堆中。
标量替换只会将对象的基本数据类型替换为栈上的标量。
-
-
Java 堆是垃圾收集器管理的主要区域,故此堆也被称为 GC 堆。由于现行的 GC 基本采用分代算法
所以 Java 堆可以细分为:新生代、老年代。
- JDK 7 及之前
- 新生代 Young Generation(细分:Eden、Survivor1、Survivor2)
- 老年代 Old Generation
- 永久代 Permanent Generation
- JDK 8 及之后
- 新生代 Young Generation(细分:Eden、Survivor1、Survivor2)
- 老年代 Old Generation
- 元空间 Metaspace
- 使用本地内存
-
对象首先在 Eden 区分配,新生代垃圾回收(YGC)后还存活,进入 S0 或 S1,且年龄增 1
当年龄到一定程度(默认:15)会晋升到老年代。
-XX:MaxTenuringThreshold可以更改阈值HotSpot 虚拟机遍历对象时,按年龄由小到大进行占用空间累加,当累加到某个年龄时,
所占空间大小超过了 Survivor 区的一半,则取这个年龄和 MaxTenuringThreshold 中更小
的一个值,作为新的晋升年龄阈值。
-
堆区域最容易出现
OutOfMemoryError,分如下几种情况:-
java.lang.OutOfMemoryError: GC Overhead Limit Exceeded当 JVM 花太多时间执行垃圾回收且只能回收很少堆空间时发生
-
java.lang.OutOfMemoryError: Java heap space创建新对象申请堆空间时发生空间不足时发生
-
- JDK 7 及之前
-
-
方法区(逻辑概念)
-
方法区属于 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域。
方法区会存储已被虚拟机加载的类信息、字段信息、方法信息、常量、静态变量、
JIT 编译器编译后的代码缓存 等数据,虚拟机规范只是这么规范这些作用,但未现在该区域如何实现。
-
方法区、永久代、元空间关系
- 方法区是逻辑区域
-
永久代是 HotSpot 虚拟机 JDK 7 及之前版本对该区域的具体实现,
- 元空间是 JDK 8 之后该区域实现,相较永久代,元空间改用本地内存来实现方法区
-
为何要将永久代替换位元空间
-
永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用本地内存
仅受本机可用内存的限制,虽仍然可能溢出,但比原永久代时发生几率变小。
-XX:MaxMetaspaceSize可以设置最大元空间大小,默认unlimited也就是默认只受系统可用物理内存限制。
-
元空间存放的事类的元数据,这样最大能加载多少类的元数据就不再被
MaxPermSize约束,而由系统的实际可用空间控制,可加载的类就变多。
JDK 7 及之前设置永久代的大小的虚拟机参数:
-XX:PermSize=N初始永久代大小-XX:MaxPermSize=N最大永久代大小 -
JDK 8 HotSpot 与 JRockit 合并代码,JRockit 是没有永久代概念,故也就移去永久代
JDK 8 之后关于元空间设置的虚拟机参数:
-XX:MetaspaceSize=N初始元空间大小-XX:MaxMetaspaceSize=N最大元空间大小,默认unlimited
-
-
运行时常量池
-
Java 字节码文件包含版本、字段、方法、接口等描述信息外还存放编译期的各种 字面量(Literal)和 符号引用 (Symbolic Reference)的常量池表。
-
常量池表会在类加载后存放在 方法区 的 运行时常量池中(Runtime Constant Pool)
注意:
运行时常量池被逻辑归类存放到方法区,而方法区是个逻辑概念
具体运行时常量池被存放到何处,由具体 JVM 实现来决定,以 HotSpot 虚拟机为例:
JDK 7 及之前,方法区的具体实现是永久代,故运行时常量池即在此内存区分配
JDK 8 之后,方法区的实现是元空间,故运行时常量池在元空间所在的本地内存区分配
-
-
字符串常量池
- JVM 为了提升性能和减少内存,对字符串 String 专门开辟一块区域,集中存取防止相同字符串重复创建,这块区域就被称作字符串常量池。
- JDK 7 之前字符串常量池被防止在永久代,之后字符串常量池被移入堆中
- 字符串常量池可以理解为固定大小的
HashTable, HotSpot VM 具体源码参考:stringTable.cppHashTable保存的是字符串为 Key,字符串对象的引用为 Value 的映射关系- 字符串常量池容量可以使用
-XX:StringTableSize参数类设置
- JDK 7 将字符串常量池移入堆中原因
- 之前版本永久代 GC 回收效率低,只能在 Full GC 才会被执行 GC,放入堆中无此限制
-
-
直接内存
- 该部分内存是特殊的内存缓冲区,并不在 Java 堆或方法区中分配,而是通过 JNI 方式在内地内存上分配
- 直接内存不属于虚拟机运行时数据区,也不是虚拟机规范中定义的内存区域,本地方法申请不到也可能触发 OOM 异常
- 直接内存最常被用来充当 NIO 模型下的 Buffer,具体对应
DirectByteBuffer对象所操作的内存,使用本地内存避免了在 Java 堆 与本地堆之间的来回复制数据。 - 直接内存分配不受 Java 堆限制,但受物理机总内存大小及处理器寻址空间限制。
-
-
-
HotSpot 虚拟机对象探秘
-
对象创建
- 类加载
- 内存分配
- 指针碰撞,已使用和未使用中间设置分界指针,分配时该指针向未使用侧移动,适合复制方式的 GC
- 空闲列表,维护可用内存块列表
- 内存分配并发问题
- 乐观锁方案:CAS+失败重试
- 线程隔离方案:TLAB 线程本地分配缓冲区,Eden 区每个线程分配一块
- 类元数据中包含该类型对象所占内存空间大小的信息(类元信息基地址 + 8 offset)
- 初始化零值
- 将对象内存中除对象头所占字节外其他字节全部初始化为零(基本类型默认值,引用类型
null)
- 将对象内存中除对象头所占字节外其他字节全部初始化为零(基本类型默认值,引用类型
- 设置对象头
- 根据类元信息设置对象头,里面包含锁状态、对象哈希值、对象 GC 分代年龄等
- 执行
init方法- 虚拟机调用特殊的
<init>方法将对象属性进行按程序员意愿的初始化
- 虚拟机调用特殊的
-
对象内存布局
-
包含三个区域:对象头、实例数据及对齐填充
-
数组类型对象在对象头中包含本对象数组长度
-
对象内存分配是按
字为最小单位,默认 8 字节,因此对象数据部分若未能构成 8 字节倍数,将填充
0比特占位
-
-
对象访问定位
- 句柄
- 堆空间维护一块句柄池,变量引用的是该池中的地址,由该地址再次指向对象实例数据
- 直接指针
- 变量引用直接指向对象的地址
- 句柄
JVM 垃圾回收
-
内存分配回收原则
- 优先 Eden 区 分配,该区无足够空间发起一次 Young GC
- Minor/Young GC 后留下的对象年龄增一,放入 Survior 幸存区
- 若幸存区空间不够将把新生代的对象提前晋升 Old 老年区
- 大对象直接进入老年区,大对象的评定标准根据不同 GC 有所不同
- Parallel Scavenge 收集器的阈值
-XX:ThresholdTolerance是根据堆内存及历史数据动态调整 - G1 收集器则根据区域大小
-XX:G1HeapRegionSize和-XX:G1MixedGCLiveThresholdPercent设置的阈值来决定对象是否可以直接进入老年代
- Parallel Scavenge 收集器的阈值
- 长期存活的对象随着年龄的递增也会进入老年区,具体晋升年龄阈值由参数
-XX:MaxTenuringThreshold设置- 垃圾收集器遍历幸存对象是也会累加占用大小,累加到已超过幸存区大小阈值
-XX:TargetSurvivorRatio设置的百分比(默认:50%)且已统计到的对象最大年龄小于晋升年龄参数,设置此年龄当做晋升年龄阈值
- 垃圾收集器遍历幸存对象是也会累加占用大小,累加到已超过幸存区大小阈值
- GC 垃圾收集器分类及目标区域
- 部分区域型 Partial GC
- 年轻代 GC:只收集 Young 区域
- 老年代 GC:只收集 Old 区域,CMS 并发收集是此模式
- 混杂 GC:收集 Young 区域及部分 Old 区域,目前 G1 有此模式
- 全区域型 Full GC
- 收集整个堆,含 Young 区、Old 区、永久区(JDK 7 及之前)
- 除 CMS 外,其他 Old 区的收集器发生 GC 时会一并收集整个堆(含 Young 区),这也是 Full GC 由来
- 因为 CMS 的例外,故 Major GC 与 Full GC 有微妙区别
- 部分区域型 Partial GC
-
空间分配担保
-
空间分配担保是为了确保在年轻代 GC 之前老年代本身可以容纳新生代所有对象的剩余空间
-
JDK 6 Update 24 之前,使用参数
-XX:HandlePromotionFailure用来设置是否允许担保失败- 允许,老年代最大连续空间小于新生代所有对象总空间且该连续空间大于历次晋升平均大小,那么此次仅进行 Young GC,尽管有老年代空间不足风险
-
JDK 6 Update 24 之后取消此参数控制,只要老年代连续空间大于新生代总大小或者历次晋升平均大小,那么此处仅进行 Young GC,否则进行 Full GC
-
-
死亡对象判断方法
-
引用计数法
- 有地方引用计数加 1,失效减 1,归零即死亡
- 难以解决循环引用的问题
-
可达性分析
-
定义 GC Roots 对象引用根起点,往下搜索形成的引用链即为成活链,除此之外即为死亡
-
GC Roots 根对象包含
- 虚拟机栈栈帧局部变量表中引用的对象
- 本地方法栈
native方法中引用的对象 - 方法区中静态属性引用的对象
- 方法区中常量引用的对象
- 所有被同步锁持有的对象
- JNI(Java Native Interface)引用的对象
-
对象可被回收,但不一定立刻被回收,需经历至少两次标记过程
- 可达性分析第一次标记,且未覆盖
finalize方法或此该方法已被虚拟机调用过,从待回收中剔除 - 待回收中留下的放入一个队列中进行第二次标记,执行回收动作
- 若该队列上某对象又被引用链任何对象建立关联也将不会被回收
- 可达性分析第一次标记,且未覆盖
-
引用类型:强、软、弱、虚 介绍参考:并发编程 - ThreadLocal 相关 小节
-
-
-
垃圾收集算法
- 标记清除算法
- 标记所有存活对象,统一回收未被标记对象
- 标记、清楚过程效率不高
- 清除后会产生内存碎片
- 复制算法
- 将内存空间分为相同两块,每次使用其中一块,回收时将存活对象复制到另一块
- 解决标记清除算法效率和内存碎片问题:每次搜索内存一半空间、复制到另一块是连续的
- 缺点:内存利用率低,不适合容量大存活对象多的分区(例如:Old 区)因为需要来回复制
- 标记整理算法
- 标记过程与标记清除算法一样,但后续是让所有存活对象向一端移动,随后清理边界之外内存
- 由于添加压缩整理环境,效率也不高,但它适合用在老年代这种内存容量大、回收频率低的场景
- 分代收集算法
- 将对象根据存活周期的不同分成几块不同的物理分区,新生代、老年代
- 根据不同区的特点选择合适的垃圾收集算法
- 新生代特点:每次有大量对象死去、分区容量较小,适合标记复制算法
- 老年代特点:对象存活率高、分区容量大、无额外分配担保,适合标记清除或标记整理算法
- 标记清除算法
-
垃圾收集器
-
根据收集区域划分不同收集器
-
年轻代收集器
- Serial
- 单线程、串行、独占式的回收器,采用标记复制算法
- 可搭配老年代收集器:CMS、Serial Old
- JDK 9 之后,不支持
Serial + CMS方式
- ParNew
- 多线程版本的 Serial 收集器
-XX:ParallelGCThread可以设置并行线程数量- 可搭配老年代收集器:CMS、Serial Old
- JDK 9 之后,不支持
ParNew + Serial Old
- Parallel Scavenge
- 多线程、串行、独占式的回收器,采用标记复制算法
- 可搭配老年代收集器:Serial Old、Parallel Old
- JDK 8 默认:Parallel Scavenge + Parallel Old
- JDK 14 弃用
Parallel Scavenge + Serial Old - 与 ParNew 相比
- 更关注吞吐量(CPU 利用率)、具备自适应调节策略
-XX:+UseParallelGC、-XX:+UseParallelOldGC分别手动开启并行方式的新生代、老年代回收模式,两个参数相互激活,开启一个另一个也被激活,若要关闭,可使用对应参数的-号
- Serial
-
老年代收集器
-
CMS
-
支持并发、多阶段的回收器,采用标记清除算法
-
关注最短的回收停顿时间,适合注重用户体验的应用
-
分四个阶段回收动作
- 初始标记:单线程串行、 STW,记录与 GC Roots 直接相连的对象,速度快
- 并发标记:与应用线程并发执行,有用户线程活动,无法保证标记的实时性
- 从初始标记记录的直连对象开始遍历对象图
- 重新标记:多线程并行、 STW,修正并发标记变动对象记录,比初始标记稍长,远短并发标记
- 只修正并发标记记录的对象的变动信息,无法获得并发标记时并发的用户线程新创建的对象
- 这些新创建对象需要到下一次 GC 时才会被释放,这些长期存在的回收对象称作浮动垃圾
- 并发清除:与应用线程并发,执行清理未标记区域
- 由于与应用并发执行,无法对内存做压缩处理,牺牲整理换取相应时间
-
缺点
-
标记清除算法产生内存碎片,可造成无法分配连续空间的大对象而频繁触发 Full GC
-
并发对 CPU 资源敏感,与应用线程并发减少了吞吐量
-
无法处理浮动垃圾
-
需要补偿机制,需 Serial Old 当做预备方案
由于并发方式需要与应用线程同时运行,对线程所需的内存资源有要求,需考虑同时工作时应用程序依然有足够的空间支持,故无法等到老年代空间几乎完全填满前就要提前开始工作,如果阈值设置不算理想会发生
Concurrent Mode Failure时,虚拟机将会启动预备方案:临时使用 Serial Old 进行老年代垃圾收集,停顿时间会相当长
-
-
JDK 9 将 CMS 标记为
Deprecate, JDK 14 已完全删除 CMS
-
-
Serial Old (MSC)
- Serial 收集器的老年代版本,单线程串行、STW 独占式的回收,采用标记整理算法
- JDK 5 及之前与 Parallel Scavenge 搭配使用
- 可用作 CMS 收集器的后背方案
-
Parallel Old
- Parallel Scavenge 收集器的老年代版本,采用多线程并行、STW 独占式回收的标记整理算法
- JDK 8 默认老年代收集器,配合年轻代 Parallel Scavenge 具备较高的吞吐量
-
-
整堆收集器
-
G1
-
G1 (Garbage First)目标是在延迟可控(低暂停)下获取尽可能高的吞吐量(高吞吐)
从而更好的利用不断扩大的内存及不断增加的处理器资源来处理高并发的业务应用
-
将整个堆分割成大小相同的不相关区域 Region,每个区域大小根据堆空间实际大小而定,整体被控制在 1 MB ~ 32 MB 之间,且为 2 的 n 次幂。
-
使用不同的区域标识逻辑上的 Eden 区、Survivor 区、Old 区,同时还增加了 Humongous 区专门用来存放大对象,单个大对象区装不下还会寻找连续的该区域,该区可以算 Old 区的部分。每个逻辑分代可以分配在不连续的多块区域之中,而且某块区域可以在不同时间标识为不同逻辑分代。
-
G1 从整体看属于标记整理算法,从局部看属于标记复制算法(区域与区域之间)。
-
有计划的规避整个堆的垃圾收集,跟踪各区域内垃圾堆积的价值大小(回收空间与时间的经验值),在后台维护一个优先级列表,每次根据允许的收集时间,优先回收价值更大的区域。由于这种侧重回收垃圾最大的区间,故而称作垃圾优先(Garbage First)
-
回收过程
-
YGC -> YGC+Concurrent Mark -> Mixed GC 然后循环,
混合回收会进行评估,若有必要会进 FullGC (单线程、独占式、高强度的,来提供保护机制)
-
当 Eden 区用尽时开始 YGC 回收(STW 多线程并行独占式收集),存活对象移动到 Survivor 或 Old 区,也可能两个区都会涉及
-
堆内存达到一定值(默认:45%)开始老年代并发标记过程,此过程一直也伴随 YGC
-
标记完成后开始混合回收处理,老年区存活对象移动到空闲区,此过程可不需要处理所有老年代对象,单次只扫描回收一部分老年代区域(价值最大),需回收的老年区域年轻代一起被回收
-
对象被不同区域引用问题解决方案:Rset (Remember Set)
当单个对象被不同区域引用时,可能出现跨年代分区引用(年轻代、老年代同时引用),此时要判断对象存活时,将不得不扫描涉及的所有年代区域,将拉低回收效率。例如:YGC 时发现对象被老年代引用,此时为了准确,YGC 不得不扫描老年代。为了避免此类问题,在每个区域中开辟 Rset 存储空间,每次讲引用类型的数据写入区域时产生写屏障,然后检测将写入的引用指向的对象是否和该引用类型数据在相同区域,若不相同,CardTable 把香港引用信息记录到引用指向对象所在的区域的 RSet 中,并将 RSet 纳入 GC Roots 范围来避免不必要的扫描。
-
-
YGC
JVM 启动准备 Eden 区,不断创建对象到 Eden 区,当该区耗尽时 G1 启动年轻代回收过程,此时会触发 STW,创建回收集 Collection Set 该集表示要被回收的内存分段集合,本次为 YGC,故而集合为 Eden 区和 Survivor 区所有内存分段。Survivor 区满不触发 GC,YGC只会回收 Eden 区(主动)和 Survivor 区(被动)。
-
扫描根
GC Roots 引用链(含 RSet)作为扫描存活对象入口
-
更新 RSet
处理 Dirty Card Queue(脏卡队列,存放发生跨分代区域引用时被引用的 RSet)队列的 Card,更新 RSet,完成此步骤可以准确反映老年代对年轻代对象的引用。
DCQ 队列在应用程序的引用赋值语句时,JVM 会在该操作前后执行特殊操作在 DCQ 中入列一个保存了对象引用信息的 Card,从而在 YGC 时不必扫描 Old 区就能获取跨代被引用的对象信息。
-
处理 RSet
将更新完成的 RSet 中存在被 Old 区引用的新生代对象标记为存活对象
-
复制对象
遍历 Eden 区对象树,存活的对象复制到 Survivor 区空闲的内存分段且对存活区年龄增一,达到晋升条件的复制到 Old 区,若幸存区空间不够,部分 Eden 数据直接晋升老年代
-
处理引用
处理软、弱、虚、JNI Weak 等引用,最终 Eden 区数据为空,GC 停止工作,而由于被复制到的目标内存对象是连续存储没有产生碎片,起到内存整理效果
-
-
并发标记过程(Old GC)
-
初始标记
标记从根节点直接可达的对象,此阶段触发 STW 及一次 YGC
-
根区域扫描
G1 扫描幸存区直接可达的老年代区域对象,并标记被引用对象,此过程在 YGC 之前完成
-
并发标记
在整堆中进行并发标记,可能被 YGC 中断。若此阶段发现某区域所有对象都是垃圾,那该区域将立即回收,同时会计算每个区域的对象存活性(区域中存活对象的比例)
-
再次标记
触发 STW 来修正并发标记时的结果,G1 采取比 CMS 更快的初始快照算法 SATB (Snapshot At The Beginning )
-
独占清理
触发 STW 计算各个区域存活对象和 GC 回收比例,并进行最大价值排序筛选出可被混合回收的区域,此阶段不做实际清理,仅提取出最大价值的优先被回收的垃圾集合
-
并发清理
识别并清理完全空闲的区域
-
-
混合回收
为避免堆内存耗尽,虚拟机触发一个混合垃圾收集器,即 Mixed GC。该算法之所以称为混合收集,是因为除了回收整个年轻代区域外,还会回收一部分老年代区域,故该回收也不被算作时 Full GC。默认情况,老年代内存分 8 次(
-XX:G1MixedGCCountTarget参数可调整该次数)完成回收,由于可以调整单次回收的多少,那么就有利于动态达到预期的延时目标。默认下,单次混合回收的回收集包括:Eden 区分段、Survivor 区分段、1/8 的 Old 区分段,采取的回收算法与年轻的回收算法一致。 混合回收也并不一定非要进行 8 次,有一项虚拟机参数可以 设置允许浪费的堆内存百分比
-XX:G1HeapWastePercent,默认 10%,意味着若发现回收的垃圾占堆内存的比例少于 10%,则不再进行混合回收。 -
可选的 Full GC
G1 初衷是要避免 Full GC,但若上述方式不能正常工作时,会触发 STW 后,使用单线程的内存回收算法进行垃圾回收,性能会非常差,应用停顿时间会很长。要避免 Full GC 发生,一旦发生需要进行调整。出现 Full GC 可能得原因:堆内存太小,复制存活对象的时候没有空的内存分段导致,可采取增大堆内存解决
-
G1 相关参数
-
通用规则参数
-XX:InitialHeapSize初始最小 Java 堆大小-XX:MaxHeapSize最大 Java 堆大小-XX:MinHeapFreeRatio最小百分比可用堆内存-XX:MaxHeapFreeRatio可用内存的最大百分比
-
G1 参数
-XX:MaxGCPauseTimeMillis期望可被接受的最大暂停时间(延时)-XX:PauseTimeIntervalMillis两次并发标记之间暂停时间间隔(吞吐量)-XX:G1NewSizePercent年轻代大小百分比-XX:G1MaxNewSizePercent最大年轻代大小百分比
-
-
优化建议
-
建议使用 G1 的默认设置,最后调整期望暂停时间,并根据需要设置最大的堆
-Xmx-
高吞吐量优先,
-XX:MaxGCPauseMillis放宽暂停时间期望或提供能打堆空间 -
低延迟优先,
-XX:MaxGCPauseMillis缩紧暂停时间期望 -
-Xlog:gc*=debug:file=/file/path/to/gclog-%p-%t.log提供更详细的 GC 日志
-
-
年轻的大小避免使用
-Xmn或-XX:NewRatio显式设置年轻代大小固定年轻代大小会覆盖暂停时间目标,原理是:G1 是通过设定可接受的最大延时(MaxGCPauseTimeMillis)、期望达到的吞吐量 (PauseTimeIntervalMillis) 这个两个目标期望,然后动态的调整年轻代大小来满足暂停时间及吞吐量期望,如果将年轻代大小固定后,将禁用暂停时间控制。
-
暂停时间目标不要设置太严苛
G1 吞吐量目标是 90% 应用时间 和 10% 垃圾回收时间
-
-
JDK 9 之后的默认垃圾回收器,被成为全功能的垃圾收集器
-
-
-
-
根据线程数划分不同收集器
- 串行回收(同一时间段内只运行单个 CPU 线程执行回收,适合单 CPU较小内存的场景)
- Serial、Serial Old
- 并行回收(同一时间段运行多个 CPU 线程同时执行回收,适合多 CPU 有吞吐量需求的场景)
- ParNew、Parallel Scavenge、Parallel Old、CMS (重新标记节点) 、G1 (最终标记、筛选回收)
- 串行回收(同一时间段内只运行单个 CPU 线程执行回收,适合单 CPU较小内存的场景)
-
根据工作模式划分不同收集器
- 独占式回收(产生 STW ( Stop-The-Word),影响应用响应时间)
- Serial、Parallel Scavenge、ParNew、Serial Old、Parallel Old、CMS (初始标记、重新标记)、G1(初始标记、最终标记、筛选回收)
- 并发式回收(与应用线程交替执行,有较高的响应性能)
- CMS (并发标记、并发清理)、G1(并发标记)
- 独占式回收(产生 STW ( Stop-The-Word),影响应用响应时间)
-
前瞻性垃圾回收器
ZGC、Shenandoah 目标高度相似,在尽可能对吞吐量影响不大的前提下,实现任意堆内存大小下都可以把垃圾收集的停顿时间限制在
10 ms以内的低延迟。-
ZGC
-
核心算法:全局空间视图切换、对象地址视图切换、STAB 算法高效并发,染色指针和内存屏障辅助
-
采取标记复制算法,可以将暂停时间控制在几毫米内,且不受堆内存大小影响,出现 STW 会更少
-
最大支持
16 TB的堆内存,在 JDK 11 中引入,在 JDK 15 已可以正式使用(-XX:+UseZGC开启) -
JDK 21 之前 ZGC 是无分代式的 GC,但此版本引入了分代 ZGC,进一步将暂停时间缩短到
1 ms内追加
-XX:+ZGenerational开启分代 ZGC
-
-
Shenandoah
Red Hat 公司开发的垃圾回收器,基于 Region 的堆内存布局,支持并发整理算法,默认不分代,不使用记忆集,改用连接矩阵。核心技术与 ZGC 类似,也采用染色指针、内存屏障等技术实现低停顿设计目标
-
-
类文件结构
参考 类文件结构详解
-
类结构
ClassFile { u4 magic; //Class 文件的标志 u2 minor_version;//Class 的小版本号 u2 major_version;//Class 的大版本号 u2 constant_pool_count;//常量池的数量 cp_info constant_pool[constant_pool_count-1];//常量池 u2 access_flags;//Class 的访问标记 u2 this_class;//当前类 u2 super_class;//父类 u2 interfaces_count;//接口数量 u2 interfaces[interfaces_count];//一个类可以实现多个接口 u2 fields_count;//字段数量 field_info fields[fields_count];//一个类可以有多个字段 u2 methods_count;//方法数量 method_info methods[methods_count];//一个类可以有个多个方法 u2 attributes_count;//此类的属性表中的属性数 attribute_info attributes[attributes_count];//属性表集合 } -
常量池
u2 constant_pool_count;//常量池的数量 cp_info constant_pool[constant_pool_count-1];//常量池常量类型
类型 标志(tag) 描述 CONSTANT_utf8_info 1 UTF-8 编码的字符串 CONSTANT_Integer_info 3 整形字面量 CONSTANT_Float_info 4 浮点型字面量 CONSTANT_Long_info 5 长整型字面量 CONSTANT_Double_info 6 双精度浮点型字面量 CONSTANT_Class_info 7 类或接口的符号引用 CONSTANT_String_info 8 字符串类型字面量 CONSTANT_FieldRef_info 9 字段的符号引用 CONSTANT_MethodRef_info 10 类中方法的符号引用 CONSTANT_InterfaceMethodRef_info 11 接口中方法的符号引用 CONSTANT_NameAndType_info 12 字段或方法的符号引用 CONSTANT_MethodHandle_info 15 表示方法句柄,Java 7 引入(运行时动态解析方法调用) CONSTANT_MethodType_info 16 标志方法类型,Java 7 引入(参数类型和返回值类型) CONSTANT_Dynamic_info 17 表示动态常量,Java 11 引入(动态常量) CONSTANT_InvokeDynamic_info 18 表示一个动态方法调用点, Java 7 引入(动态调用支持) CONSTANT_Module_info 19 表示模块的符号引用,Java 9 引入 CONSTANT_Package_info 20 表示包的符号引用,Java 9 引入 -
访问标志
u2 access_flags;//Class 的访问标记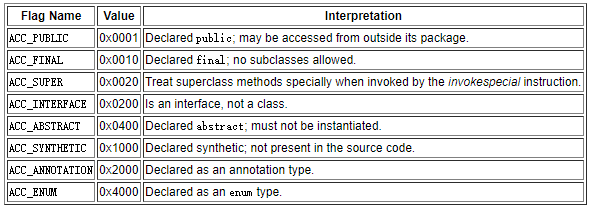
-
当前类、父类、接口
u2 this_class;//当前类 u2 super_class;//父类 u2 interfaces_count;//接口数量 u2 interfaces[interfaces_count];//一个类可以实现多个接口 -
字段表集合
u2 fields_count;//字段数量 field_info fields[fields_count];//一个类会可以有个字段
字段访问修饰标志

-
方法表集合
u2 methods_count;//方法数量 method_info methods[methods_count];//一个类可以有个多个方法
方发表访问修饰符

-
属性表集合
u2 attributes_count;//此类的属性表中的属性数 attribute_info attributes[attributes_count];//属性表集合属性表在 Class 文件、字段表、方法表中都可以出现来描述相应结构中的专有信息,例如:方法表中的
code属性包含方法的具体源代码编译后相对应的字节码指令。 -
实战解析
-
源码
package demo; /** * @author Reion **/ public class People { public String name; public int age; }package demo; /** * @author Reion **/ public class Student extends People { public int id; }查看
Student.class二进制文件
-
类加载过程
-
加载
- 通过全限定名获取此类的字节码文件,读入二进制流
- 将字节流代表的静态存储结构(常量池表、静态变量)转换为方法区的运行时数据结构
- 在内存中生成一个代表该类的
Class类型的对象实例,作为方法区数据结构的访问入口
-
链接
-
验证
- 字节码文件格式验证
- 元数据验证(字节码语义检查)
- 字节码校验(程序字节码指令检查)
- 符号引用验证(类的正确性检查)
-
准备
-
为类变量分配内存并设置类变量初始值(默认值)
基本类型
0、false、0L等引用类型
null此时即使是常量(例如: static final int VALUE = 123 ) ,此刻
VALUE也只被赋默认值0把
123赋值给VALUE需要到编译的静态初始化方法<clinit>()被执行时才会执行生效。此外,基本类型、字符串类型的常量(static final)其相应的字面量将会被编译器放入字段的
ConstantValue属性中,同时直接赋值初始化,而不会使用<clinit()>初始化,只有使用静态代码块完成的初始化才会生成
<clinit()>在里面执行常量的赋值操作。另外:被
final修饰的变量(不管是类变量或成员变量)都会生成ConstantValue属性表只是类变量的
final型(基本类型、字符串的静态代码块初始化、其他类型=、静态代码块赋值)在 生成的<clinit>()完成初始化,而对象成员变量的final型统统在init<>构造方法完成初始化 -
这些内存都将在方法区分配
类变量的内存逻辑上在方法区,HotSpot 在 JDK 7 及之后此部分已放入堆中,准确的说静态变量被分配在该类的
Class类型对象实例中(实例对象都在堆中分配),此外字符串常量池也被放入堆中。
-
-
解析
- 虚拟机在此阶段将常量池内的符号引用替换为直接引用的过程,主要包括类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符 7 类符号引用进行。
-
-
初始化
-
执行初始化方法
<clinit>()方法的过程,是类加载的最后一步,也是开始执行类中定义的 Java 程序代码。 -
初始化阶段,虚拟机规范有 6 种情况下,对类进行初始化(主动使用才会初始化类)
-
遇到
new、getstatic、putstatic或invokestatic四个字节码指令对应实例化对象、访问类的静态变量、给静态变量赋值、调用类的静态方法
-
使用反射方法对类进行调用,如:
Class.forName("...")、newInstance()等 -
初始化一个类,其父类还未初始化,触发父类的初始化
-
虚拟机启动时,包含
main方法的主类会先初始化 -
MethodHandle、VarHandler轻量级的反射调用机制,它们会使用findStaticVarHandle初始化目标类 -
实现接口的默认方法的类初始化前,触发该接口的初始化
-
-
-
使用
- 类的运行时都已完成且初始化之后,就可以正常使用该类
-
卸载
- 该类对应的 Class 类型对象被 GC 回收被称作类的卸载,需满足 3 个条件
- 该类的所有实例对象都已被 GC 回收
- 该类的实例没有在其他任何地方被引用
- 该类的类加载器的实例已被 GC 回收
- 由此得知,由系统内置的类加载器加载的类不会被回收,因为这些加载器实例是不会被回收的
- 该类对应的 Class 类型对象被 GC 回收被称作类的卸载,需满足 3 个条件
类加载器
-
类加载器
-
类加载器负责加载类的对象,完成上节类加载生命周期中的加载过程
-
每个 Java 类都有一个引用指向加载它的
ClassLoader -
数组类不是通过
ClassLoader加载的,数组类的对象的ClassLoader对应的是其元素类型相关联的ClassLoader,基本类型的数组类型对象是没有与之相关的ClassLoader -
类加载器是加载字节码文件到 JVM 中,并在内存中生成一个代表该类的
Class的对象,而字节码可以是编译器编译源代码文件(Java、Kotlin 等源文件),也可以是通过工具动态生成的,甚至来源于网络。 -
类是根据需要动态加载,已加载的类对象放在
ClassLoader实例的变量classespublic abstract class ClassLoader { ... private final ClassLoader parent; // 由这个类加载器加载的类。 private final Vector<Class<?>> classes = new Vector<>(); // 由VM调用,用此类加载器记录每个已加载类。 void addClass(Class<?> c) { classes.addElement(c); } ... } -
内置的
ClassLoader-
BootstrapClassLoader启动类加载器,逻辑顶层的加载类,由 C++ 实现,通常表示为
null, 且没有父级。主要用作加载 JDK 内部的核心类库:%JAVA_HOME%/lib路径下的 jar 包 -
ExtClassLoader/PlatformClassLoader扩展类加载器,负责加载路径
%JAVA_HOME%/lib/ext目录、java.ext.dirs环境变量下的 jar 包和类。JDK 9 之后,扩展类加载器被更改为平台类加载器,除几个关键模块外,其余模块是由此平台类加载器加载 -
AppClassLoader应用程序类加载器,面向用户的加载器,负责加载当前应用环境变量
classpath下的所有 jar 包和类 -
三者逻辑关系(非继承关系)
BootClassLoader ^ | 逻辑上级加载器 ExtClassLoader (JDK 8 及之前) | PlatformClassLoader(JDK 9 及之后) ^ | 逻辑上级加载器 AppClassLoader (自定义 ClassLoader 的逻辑上级)注意,它们之间的上下级关系是通过组合实现的,而非利用类的继承关系实现,例如:AppClassLoader 持有一个 ExtClassLoader 类型的 parent 引用。
-
-
-
双亲委派模型(父辈委派更贴切)
双亲委派代码非常简单,集中在
java.lang.ClassLoader的loadClass()中:protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { //首先,检查该类是否已经加载过 Class c = findLoadedClass(name); if (c == null) { //如果 c 为 null,则说明该类没有被加载过 long t0 = System.nanoTime(); try { if (parent != null) { //当父类的加载器不为空,则通过父类的loadClass来加载该类 c = parent.loadClass(name, false); } else { //当父类的加载器为空,则调用启动类加载器来加载该类 c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { //非空父类的类加载器无法找到相应的类,则抛出异常 } if (c == null) { //当父类加载器无法加载时,则调用findClass方法来加载该类 //用户可通过覆写该方法,来自定义类加载器 long t1 = System.nanoTime(); c = findClass(name); //用于统计类加载器相关的信息 sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { //对类进行link操作 resolveClass(c); } return c; } }- 类加载的时候,系统会首先判断当前类是否被加载过,已加载直接返回,否则委托父辈加载器加载
- 每个被委托的父辈加载器先判断是否已被自身加载,已加载直接返回,否则同样委托它自己的父辈加载器尝试,直到顶级加载器 BootClassLoader
- 当顶层加载器发也无发现该类,加载器才调用自身的
findClass()去尝试加载 -
若自身也无法加载该类,抛出
ClassNotFoundException -
父辈委派好处
- 核心 API 确保不被篡改
-
避免重复加载
-
打破父辈委派
-
实现方式:重写
ClassLoader的loadClass()方法 -
打破需求场景
-
Tomcat Servlet 容器的
WebAppClassLoader单个 Tomcat 服务器启动单个 JVM 虚拟机,为了实现多个 Web 应用之间、单个 Web 应用不同版本之间都能部署在该单个容器中启动运行,那么就要解决通用类应用间共享、相同类不同版本间隔离等需求,而后者隔离需求就需要打破父辈委派来实现
-
Java SPI 机制的接口
例如:
java.sql.Driver是 Java 核心库提供,由BootstrapClassLoader加载,根据父辈委派原则,它是无法加载由AppClassLoader加载的第三方数据库提供的驱动器实现的,必然要打破实现
-
-
JVM 重要的参数
此处讨论的所有虚拟机参数是基于 JDK 8,除非特别说明。
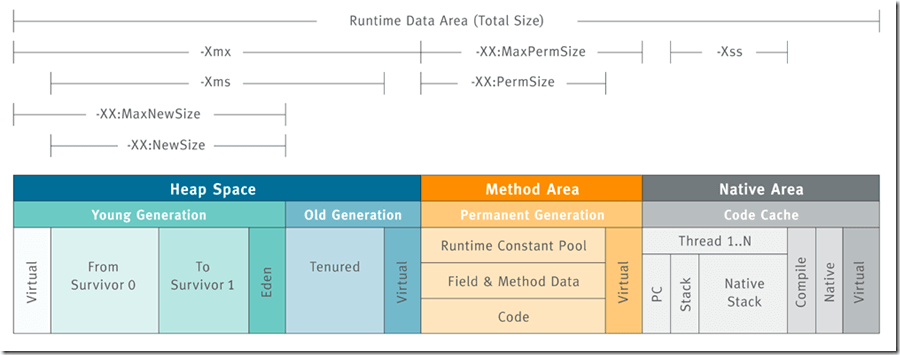
-
堆内存相关
-
堆内存显式指定参数
-Xms<heap size>[unit] #最小堆大小 -Xmx<heap size>[unit] #最大堆大小- heap size 表示堆数值大小
- unit 表示堆数值对应的内存单位大小,单位可以为:
g(GB)、m(MB)、k(KB)
-
新生代内存显式指定参数
两种指定方式
-
方式一
-XX:NewSize=<young size>[unit] #最小新生代大小 -XX:MaxNewSize=<young size>[unit] #最大新生代大小 -
方式二
-Xmn<young size>[unit] #最小最大一致的新生代大小
此外,可以通过
-XX:NewRatio=<int>设置老年代与新生代的比值。 -
-
永久代/元空间显式指定参数
Java 8 之后,永久代已被元空间替代,而元空间分配在本地内存空间,若不设置大小可能会将系统内存耗尽。
-
JDK 8 之前调整永久代
-XX:PermSize=N #方法区 (永久代) 初始大小 -XX:MaxPermSize=N #方法区 (永久代) 最大大小,超过抛出: java.lang.OutOfMemoryError: PermGen -
JDK 8 及之后调整元空间
-XX:MetaspaceSize=N #设置元空间触发 Full GC 的阈值,元空间默认大小由平台决定,范围 12MB~20MB -XX:MaxMetaspaceSize=N #设置元空间的最大大小元空间不断扩容到
-XX:MetaspaceSize指定的参数值后,会触发 Full GC,并且之后每次发生元空间扩容都会触发 Full GC,所以该参数只是起到 Full GC 阈值作用,而非初始化元空间大小。
-
-
-
垃圾收集相关
-
指定垃圾收集器
JDK 8 默认采取 PS + PO 的垃圾收集器方式,下面参数可以变换收集器:
-XX:+UseSerialGC # Se + SO (Serial + Serial Old) -XX:+UseParallelGC # PS + PO (Parallel Scavenge + Parallel Old) -XX:+UseParNewGC # PN + SO (ParNew + Serial Old) 将过期 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC # PN + CMS (ParNew + CMS) -XX:-UseParNewGC -XX:+UseConcMarkSweepGC # Se + CMS (Serial + CMS)将过期 -XX:+UseG1GC # G1-
-XX:+UseParNewGC参数设置 PN + SO 会收到警告提示:Java HotSpot(TM) 64-Bit Server VM warning: Using the ParNew young collector with the Serial old collector is deprecated and will likely be removed in a future release -
-XX:-UseParNewGC结合-XX:+UseConcMarkSweepGC参数设置 Se + CMS 会收到警告提示:Java HotSpot(TM) 64-Bit Server VM warning: Using the DefNew young collector with the CMS collector is deprecated and will likely be removed in a future release
-
-
查看运行时的应用使用的垃圾收集器
-
利用
jconsole工具的 VM 概要 选项卡页面查看,此方式垃圾收集器名称为内部名称,与别名对照如下工具显示名称 对应常用别名 Copy Serial、DefNew MarkSweepCompact Serial Old、MSC PS Scavenge Parallel Scavenge、PSYoungGen PS MarkSweep Parallel Old ParNew ParNew ConcurrentMarkSweep CMS G1 Young Generation G1 G1 Old Generation G1 参考资料:
-
利用可视化工具 JDK Mission Control
-
-
GC 日志记录
# 必选 # 打印基本 GC 信息 -XX:+PrintGCDetails -XX:+PrintGCDateStamps # 打印对象分布 -XX:+PrintTenuringDistribution # 打印堆数据 -XX:+PrintHeapAtGC # 打印Reference处理信息 # 强引用/弱引用/软引用/虚引用/finalize 相关的方法 -XX:+PrintReferenceGC # 打印STW时间 -XX:+PrintGCApplicationStoppedTime # 可选 # 打印safepoint信息,进入 STW 阶段之前,需要要找到一个合适的 safepoint -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1 # GC日志输出的文件路径 -Xloggc:/path/to/gc-%t.log # 开启日志文件分割 -XX:+UseGCLogFileRotation # 最多分割几个文件,超过之后从头文件开始写 -XX:NumberOfGCLogFiles=14 # 每个文件上限大小,超过就触发分割 -XX:GCLogFileSize=50MJDK 8 及之前版本:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<file-path>JDK 9 及之后版本:
-Xlog:gc*:file=<file-path>其他建议参数:
-XX:+HeapDumpOnOutOfMemoryError -XX:ErrorFile=/logs/oom_dump/xxx.log -XX:HeapDumpPath=/logs/oom_dump/xxx.hprof -XX:+ExitOnOutOfMemoryError -XX:NativeMemoryTracking
-
-
处理 OOM
将堆内存转存到一个物理文件中,用来查找内存泄漏
-XX:+HeapDumpOnOutOfMemoryError # 指示 JVM 遇到 OOM 时将堆转成物理文件中 -XX:HeapDumpPath=./java_pid<pid>.hprof # 设置转存文件路径 -XX:OnOutOfMemoryError="< cmd args >;< cmd args >" # 内存不足发出紧急命令 -XX:+UseGCOverheadLimit # 限制抛 OOM 之前在 GC 中花费的 VM 时间比例 -
其他
-server: 启用“ Server Hotspot VM”; 此参数默认用于 64 位 JVM-
-XX:+UseStringDeduplication: Java 8u20 引入了这个 JVM 参数,通过创建太多相同 String 的实例来减少不必要的内存使用; 这通过将重复 String 值减少为单个全局char []数组来优化堆内存。 -XX:+UseLWPSynchronization: 设置基于 LWP (轻量级进程)的同步策略,而不是基于线程的同步。-XX:LargePageSizeInBytes: 设置用于 Java 堆的较大页面大小; 它采用 GB/MB/KB 的参数; 页面大小越大,我们可以更好地利用虚拟内存硬件资源; 然而,这可能会导致 PermGen 的空间大小更大,这反过来又会迫使 Java 堆空间的大小减小。-XX:MaxHeapFreeRatio: 设置 GC 后, 堆空闲的最大百分比,以避免收缩。-XX:SurvivorRatio: eden/survivor 空间的比例, 例如-XX:SurvivorRatio=6设置每个 survivor 和 eden 之间的比例为 1:6。-XX:+UseLargePages: 如果系统支持,则使用大页面内存; 请注意,如果使用这个 JVM 参数,OpenJDK 7 可能会崩溃。-XX:+UseStringCache: 启用 String 池中可用的常用分配字符串的缓存。-XX:+UseCompressedStrings: 对 String 对象使用byte []类型,该类型可以用纯 ASCII 格式表示。-XX:+OptimizeStringConcat: 它尽可能优化字符串串联操作。
JDK 附带工具
-
JDK 命令行工具
-
jps(Java Process Status)类似
ps命令,查看 Java 进程启动类、传入参数及虚拟机参数,查看使用说明 -
jstat(JVM Statistics Monitoring Tool)收集 HotSpot 虚拟机各方面的运行数据,查看使用说明
# 命令格式 Usage: jstat --help|-options jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]] # 可观察的选项 jstat -options -class # 显示类加载情况统计 -compiler # 显示 JIT 编译统计信息 -gc # 显示 GC 行为的堆统计信息 -gccapacity # 显示各分代的容量信息 -gccause # 显示垃圾收集汇总统计信息(与 gcutil 一致),附带上次及当前 GC 的触发原因 -gcmetacapacity # 显示元空间容量信息 -gcnew # 显示年轻代的回收行为统计 -gcnewcapacity # 显示年轻代容量信息 -gcold # 显示老年代、元空间的回收行为统计 -gcoldcapacity # 显示老年代容量信息 -gcutil # 显示垃圾回收汇总统计信息 -printcompilation # 显示 Java HotSpot 虚拟机编译方法统计信息 -
jinfo(Configuration Info for Java)显示虚拟机配置信息,查看使用说明
-
jmap(Memory Map for Java)主动生成堆转存快照,查看使用说明
-
使用
-XX:+HeapDumpOnOutOfMemoryError参数,可以使虚拟机在 OOM 异常时自动生成 dump 文件,Linux 系统通过kill -3给应用进程也能触发生成 dump 文件 -
其他可选项
# 命令格式 Usage: jmap [option] <pid> (to connect to running process) jmap [option] <executable <core> (to connect to a core file) jmap [option] [server_id@]<remote server IP or hostname> (to connect to remote debug server) # 可选项 where <option> is one of: -heap # 打印 java 堆汇总信息 -histo[:live] # 打印堆中对象的直方图,加载参数 live 只显示存储对象统计 -clstats # 打印类加载统计信息 -finalizerinfo # 打印对象等待 finalization 的对象信息 -dump:<dump-options> # 导出 hprof 二进制格式的文件 dump-options: live # 仅仅导出存活对象 format=b # 指定二进制格式 file=<file> # 指定导出文件路径 # 例如:jmap -dump:live,format=b,file=heap.bin <pid>
-
-
jhat(JVM Heap Dump Browser)用于分析堆转存快照文件 heapdump,会建立一个 Http 的服务器,用户可在浏览器查看分析结果,查看使用说明
# 命令格式 Usage: jhat [-stack <bool>] [-refs <bool>] [-port <port>] [-baseline <file>] [-debug <int>] [-version] [-h|-help] <file> # 可选项 -port <port>: # 设置 Http 服务端口,默认 7000 <file> # 堆转存文件 -
jstack(Stack Trace for Java)生成虚拟机当前时刻的线程快照,显示每一条线程当下执行的方法堆栈,查看使用说明
可以显示快照时线程所处状态,对于排除线程死锁、死循环、等待时间过长等问题有帮助。
JDK 附带工具众多,详细请查阅
-
-
JDK 可视化分析工具
-
JConsole一款图形化的健康及管理 Java 应用的控制台,查看使用说明
不但可以监控本地应用,远程应用启动时追加如下参数:
# 应用所在主机的外网地址 -Djava.rmi.server.hostname=外网访问 ip 地址 # JMX RMI 监听端口 -Dcom.sun.management.jmxremote.port=60001 # 禁用认证(请勿在生产环境使用) -Dcom.sun.management.jmxremote.authenticate=false # 禁用 SSL 链接(请勿在生产环境使用) -Dcom.sun.management.jmxremote.ssl=false在
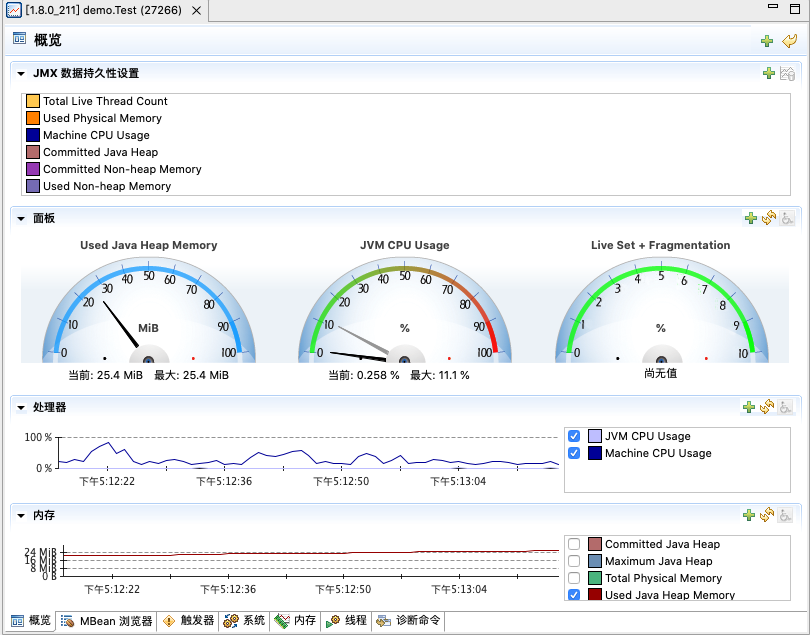
JConsole连接配置面板输入远程的应用 IP 地址、端口号及认证信息即可启动监控-
Java 程序概览
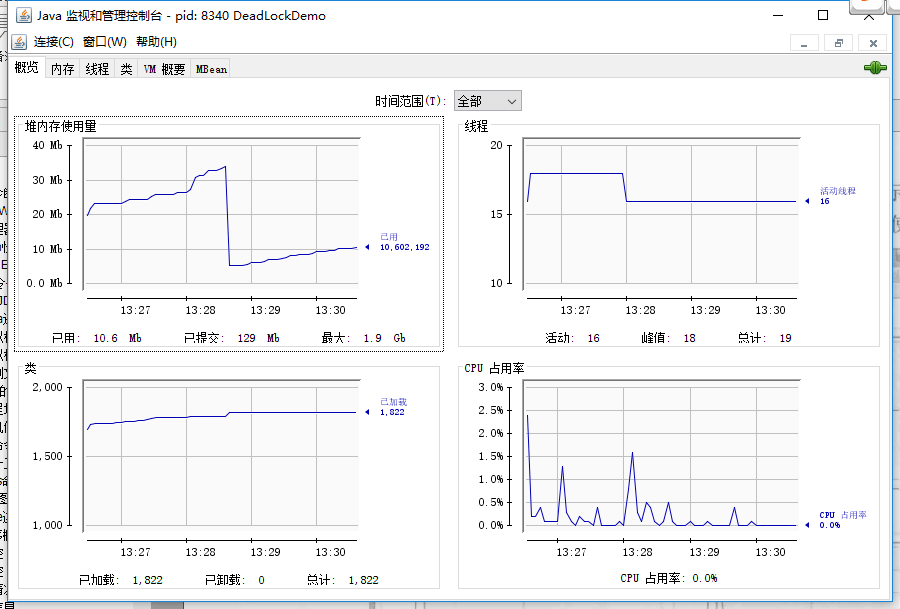
-
内存监控
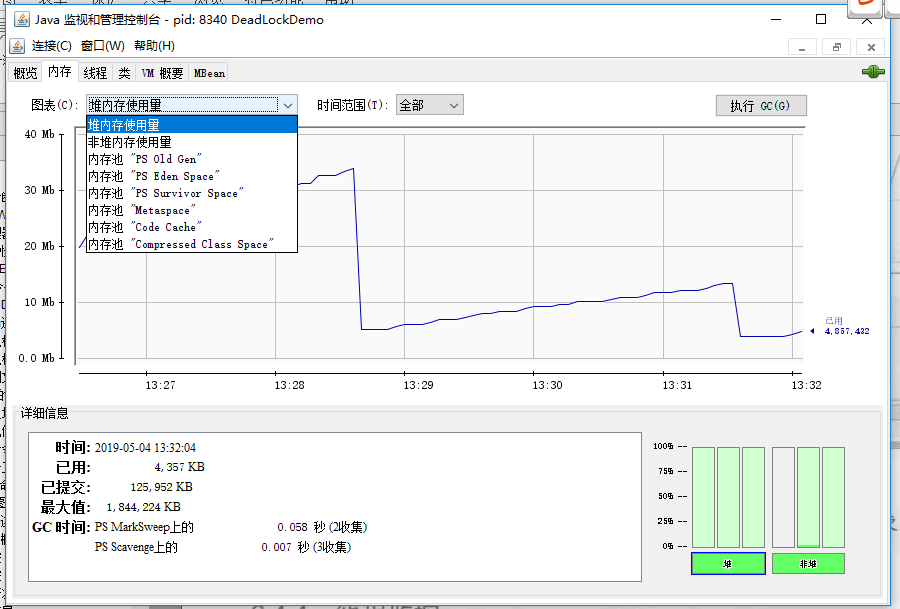
可以浏览不同堆分区的内存使用情况,并且可以手动触发 GC
-
线程监控
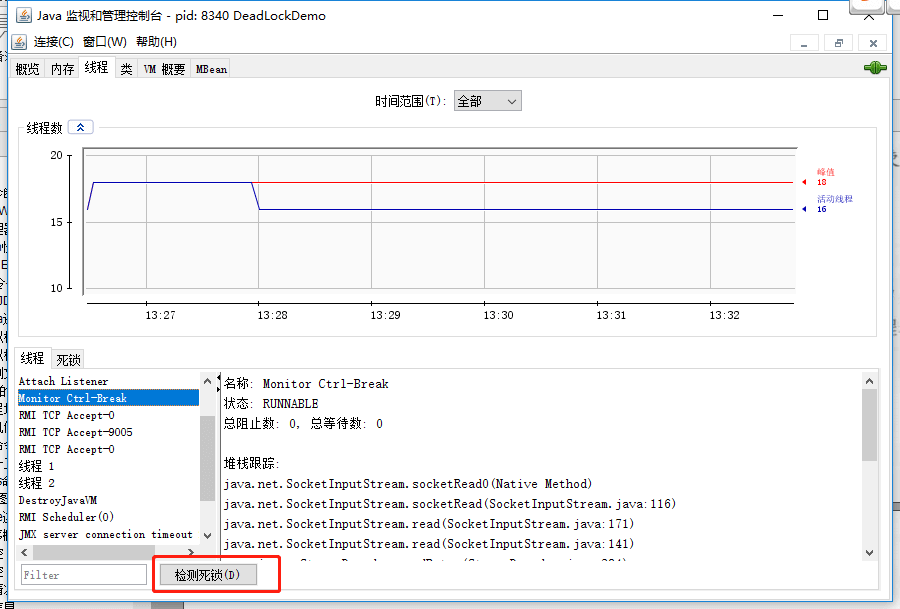
检测死锁工具 能快速查询到死锁线程及它们的详细信息
-
-
VisualVMVisualVM是一款集成 JDK 命令行工具,具备轻量化分析功能的可视化工具,适用于开发环境、生产环境。
-
JMC(Java Mission Control)JMC是一款用来管理、监控、分析以及问题跟踪 Java 应用程序的高级工具集,JMC 可以对代码性能、内存和延迟等领域进行高效、详细的数据分析,而不会引入通常与分析和监控工具相关的性能开销。JDK Mission Control 版本 8.3.1 (JMC 8) 现已可供下载。 JMC 8 提供了新的依赖关系视图、热图视图、用于访问 JFR 堆栈跟踪的 Websocket 服务器、火焰图视图、增强的规则 API 以及对功能和可用性的其他改进。 JMC 8 取代 JMC 7,所有 JMC 7 用户和任何剩余的 JMC 5 用户都应升级到此新版本。 JMC 8 现在能够分析 JDK 7 及更高版本的记录。有关更多详细信息,请参阅JMC 8 OpenJDK 项目页面。
-
JVM 排查和调优
CMS GC 问题分类
-
发生非预期的意外 GC
-
空间震荡:动态扩缩容引起的空间震荡
-
现象:GC 次数多、最大空间剩余多、GC 原因显示 Allocation Failure、每次 GC 堆内各空间大小有变动
-
原因:
-Xms、-Xmx设置不一致时在堆内内存负载变化频繁时引起动态扩缩容 -
策略:观察 GC 触发时间点各个区的 committed 占比是不是一个固定值
-
解决:尽量将成对出现的空间大小配置设置成固定(除非特别说明)
若不追求停顿时间,动态扩缩容有利于节省空间
-
-
显式 GC:显式执行
System.gc()- 现象:老年代、元空间剩余容量充足,年轻代无晋升失败,大对象分配担保正常,还是触发了 GC
- 原因:显示调用
System.gc()会引发 Full GC,对整个堆进行 GC - 策略:CMS GC 分前台后台两种模式,后台是并发收集,前台时会进行压缩整理年轻、老年代、元空间,该模式代价巨大,若频繁被显式调用不可取,但若将显示调用方法禁用,将影响虚拟机对直接内存映射方式所占空间的回收,推荐保留。
- 解决:
-XX:+ExplicitGCInvokesConcurrent、-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses两参数可将调用改为后台模式,该模式也会做前台模式相同操作,且能降低 STW 开销,也会对直接内存区域做回收。
-
-
部分区域 GC
- 年轻代 GC:年轻代过早晋升导致频繁 GC
- 现象:对象年龄达到
-XX:MaxTenuringThreshold会伴随晋升,该阈值会根据新生代存活对象所占幸存区大小的一半以上而变动,当发射过早晋升可能:分配速率过快幸存区容量较小触发、Full GC 频繁且之后老年代变化比例非常大(晋升对象存活时间短) - 原因:年轻代分配过小、内存分配速率过大
- 策略:观察老年代存活对象大小,将老年代设置在存活对象的 2 至 3 倍,剩下分配给年轻代,若是分配速率过大,如果是偶发从业务逻辑做优化,若一直较大,升级物理硬件达到期望吞吐量或更改 GC 类型
- 解决:过早晋升后观察晋升后对象的存活率,若存活率高统计大小,按照策略中的推荐修改各分区大小,若是分配速率过大,要求系统满足吞吐量、业务要求,可以根据以下衡量指标进行软硬件优化:
- 年轻的与年老代的比例 R 与对象分配速率 Va、对象晋升速率 Vp、YGC速率 Vy、OGC速率 Vo、老年代对象存活率 Rs有相关性
- Rs 小、Va 大、Vp 大、Vy 大、Vo 大 时,增大 R
- 两次 YGC 间隔大于 TP9999 时间,避免让新生代短期对象在年轻代就被回收
- 年轻的与年老代的比例 R 与对象分配速率 Va、对象晋升速率 Vp、YGC速率 Vy、OGC速率 Vo、老年代对象存活率 Rs有相关性
- 现象:对象年龄达到
- 老年代 GC:
- 老年代频繁 GC
- 现象:频繁 Old GC,但耗时不算长, STW 可接受范围,频繁 GC 吞吐量下降
- 原因:YGC 完成后,CMS GC 会间隔
-XX:CMSWaitDuration检测是否达到回收条件,来启动后台 CMS GC,触发条件分为下面几种情况:- CMS 收集运行时数据判断是否触发,或读取参数
-XX:CMSInitiatingOccupancyFraction的值进行判断,要忽略前者使后者生效,需配置-XX:+UseCMSInitiatingOccupancyOnly,默认老年代占用率达到 92% 触发 CMS GC - YGC 失败过,下一次再失败也可能触发 CMS GC,CMS GC 只处理老年代,不处理元空间,可以通过配置
-XX:+CMSClassUnloadingEnabled支持元空间收集
- CMS 收集运行时数据判断是否触发,或读取参数
- 策略:此现象可能是对象存活时间长于 TP9999 发生晋升,但又不长期存活(网络连接、失效缓存),一般对比分析 CMS GC 前后 dump 文件,查看 Top Component、几种不同引用类型,重点查看 Unreachable,关注 Shallow 和 Retained 大小
- 解决:即时处理资源回收,尽可能缩短这些对象在堆中的存货时间
- 不频繁,单次耗时长
- 现象:CMS GC 不频繁,但是单次 STW 超过 1000 ms
- 原因:CMS GC 初始标记、最终标记两阶段可能出现 STW 长耗时的情况,初始化标记从 GC Root 出发,标记 Old 对象,借助 BitMap 处理年轻的到 Old 区的引用,最终标记后续多了 Card Table 遍历、引用实例清理等耗时操作
- 策略:
-XX:+PrintReferenceGC观察 Final Remark 中 Reference 处理,排查原因中的步骤耗时 - 解决:若是清理引用耗时,可以增加
-XX:+ParallelRefProcEnabled对引用并行处理,观察元空间符号引用时间长,关闭 CMS GC 处理元空间的开关
- 老年代频繁 GC
- 年轻代 GC:年轻代过早晋升导致频繁 GC
-
全量 GC
-
内存碎片多、收集器退化
-
原因:CMS GC 由于是标记清理算法可能带来碎片化问题,需要退化为单线程串行 GC 模式来回收整理,退化后的串行 GC you两种算法:
- 带压缩动作的算法 MSC
- 不带压缩动作的算法,仅收集 Old 区,比 MSC 暂停时间短
导致退化原因有:碎片化导致晋升失败、增量收集担保失败、显式 GC、并发模式失败(浮动垃圾引起)
-
策略:
- 内存碎片问题,可通过
-XX:UseCMSCompactAtFullCollection=true开启 Full GC 的压缩整理,同时结合-XX:CMSFullGCsBeforeCompaction=n来控制压缩频次 - 降低出发 CMS GC 的阈值,尽可能早的让 CMS GC 介入保证 Old 区空间
- 浮动垃圾:
-XX:+CMSScavengeBeforeRemark提前出发一次 YGC 防止 CMS 过程中过多的晋升对象
- 内存碎片问题,可通过
-
-
-
元空间
- 现象:元数据空间已使用大小持续增长,GC 无法释放、调大元空间也无法彻底解决
- 原因:MetaSpace 主要由 Klass MetaSpace 和 NoKlass MetaSpace 两大部分组成
- Klass MetaSpace 用来存 Klass 即 Class 文件在 JVM 运行时的数据结构,默认放入 Compressed Class Pointer Space 中,是一块连续内存区域,紧挨着 Heap。该区域非必须,当禁止了类地址指针压缩或最大堆大小大于 32 G 时,就不会有这块区域,将 Klass 存入 NoKlass MetaSpace 里
- NoKlass MetaSpace 专门存放 Klass 相关的其他内容,如 Method、ConstantPool 等,可由多块不连续内存组成,当禁用类指针压缩时也会存放 Klass 信息
- Klass 运行时数据由类加载器动态的加载新 Class 而产生,元空间持续增长一般都在动态类加载且由于类加载器一直存活无法回收其加载的所有 Klass 数据
- 策略:使用
jcmd、JProfiler 等工具查看 dump 快照的对象 Histogram 图,留有元数据区相关指标,或者增加-XX:+TraceClassLoading、-XX:+TraceClassUnLoading观察类加载卸载信息。一般产生原因是一些动态类加载的工具如:CGLIB 动态代理、Groovy 动态加载类、JSON ASMSerializer、反射、OSGI 自定义类加载器等技术不断往此区域生成类相关信息 - 解决:给元数据空间的使用率加监控,并给定合理范围内的大小容量
-
直接内存
- 直接内存回收引发问题
- 现象:top 命令 Java 进程 RES 超过
-Xmx大小,GC 时间飙升,线程阻塞 - 原因:堆外内存泄漏:可能代码申请堆外内存没释放(NIO、Netty)或 JNI 调用本地代码未释放内存
- 策略:
-XX:NativeMemoryTracking=detail追踪堆外内存分配、jcmd pid VM.native_memory detail查看内存分布 - 解决:
-XX:MaxDirectMemorySize=size控制堆外内存最大值、检测是否禁用了显示 GC;若是 JNI 调用本地方法内存未释放,使用 Google perftools + Btrace 工具分析具体问题代码位置
- 现象:top 命令 Java 进程 RES 超过
- 直接内存回收引发问题
-
本地方法
- 本地方法引发问题
- 现象:GC 原因显示 GCLocker Initiated GC
- 原因:Java 调用本地方法,本地方法可能直接使用 JVM 堆区指针,若 GC 的安全暂停点不恰当时会导致数据错误。在发生 JNI 调用时,线程 JNI 进入临界区后,是禁止 GC 的发生,并阻止其他线程进入 JNI 临界区,直到线程退出临界区后才出发 GC。但 GC Lock 可能有不良后果:
- 年轻代分配内存异常,在锁定区间将无法 YGC,直接奖对象分配到 Old 区
- Old 区没空间,则会等待 GC Lock 释放,导致线程阻塞
- 策略:
-XX:PrintJNIGCStalls参数打印 JNI 调用时的线程,找出引发问题的 JNI 调用,谨慎使用 JNI 调用,升级 JDK 版本等操作
- 本地方法引发问题
GCeasy GC 日志分析报告
新特性
Java 8 (LTS)
-
接口默认方法
- 可以用
default或static修饰接口方法,使方法有方法体 - 实现两个接口,且两个接口有同名默认方法,实现类必须重写同名方法
- 接口与抽象类区别
- 接口允许多继承、抽象类单继承
- 接口方法修饰符
public abstract,变量public static final抽象类可以使用其他修饰符
- 可以用
-
函数式接口
- 有且仅有一个抽象方法,但可有多个非抽象方法的接口,称作函数式接口
- 可以被
@FunctionalInterface注解,并非一定要被其注解
-
Lambda 表达式 (语法糖)
-
语法格式
(parameters) -> expression; // 或者 (parameters) -> { statements; } -
便利性
-
替代匿名内部类
new Thread(() -> {statements}); -
集合迭代
Arrays.asList("1", "2", "3").forEach(s -> System.out.println(s)); -
方法引用
Arrays.asList("1", "2", "3").forEach(Integer::parseInt); -
访问变量
// final 修饰、或确保之后不被修改的变量,可被纳入表达式闭包中 final int x = 1; int y = 1; Arrays.asList(1, 2, 3).stream().filter(n -> n > x && x < y).count();
-
-
-
Stream 流
-
类型:stream 串行流、parallelStream 并行流,可多线程执行
-
常见方法
/** * 返回一个串行流 */ default Stream<E> stream() /** * 返回一个并行流 */ default Stream<E> parallelStream() /** * 返回T的流 */ public static<T> Stream<T> of(T t) /** * 返回其元素是指定值的顺序流。 */ public static<T> Stream<T> of(T... values) { return Arrays.stream(values); } /** * 过滤,返回由与给定predicate匹配的该流的元素组成的流 */ Stream<T> filter(Predicate<? super T> predicate); /** * 此流的所有元素是否与提供的predicate匹配。 */ boolean allMatch(Predicate<? super T> predicate) /** * 此流任意元素是否有与提供的predicate匹配。 */ boolean anyMatch(Predicate<? super T> predicate); /** * 返回一个 Stream的构建器。 */ public static<T> Builder<T> builder(); /** * 使用 Collector对此流的元素进行归纳 */ <R, A> R collect(Collector<? super T, A, R> collector); /** * 返回此流中的元素数。 */ long count(); /** * 返回由该流的不同元素(根据 Object.equals(Object) )组成的流。 */ Stream<T> distinct(); /** * 遍历 */ void forEach(Consumer<? super T> action); /** * 用于获取指定数量的流,截短长度不能超过 maxSize 。 */ Stream<T> limit(long maxSize); /** * 用于映射每个元素到对应的结果 */ <R> Stream<R> map(Function<? super T, ? extends R> mapper); /** * 用于映射集合类型到对应的结果,传入展开函数 */ <R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper); /** * 根据提供的 Comparator进行排序。 */ Stream<T> sorted(Comparator<? super T> comparator); /** * 丢弃流中的前 n 个元素后的流 */ Stream<T> skip(long n); /** * 返回一个包含此流的元素的数组。 */ Object[] toArray(); /** * 使用提供的 generator函数返回一个包含此流的元素的数组,以分配返回的数组,以及分区执行或调整大小可能需要的任何其他数组。 */ <A> A[] toArray(IntFunction<A[]> generator); /** * 合并流 */ public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) -
map() 和 flatMap()
List<String[]> listOfArrays = Arrays.asList( new String[]{"apple", "banana", "cherry"}, new String[]{"orange", "grape", "pear"}, new String[]{"kiwi", "melon", "pineapple"} ); // ------------- map ------------------------- // map 方法如果不做类型转换,则生成的流的类型是 String[] Stream<String[]> chgMapStream = listOfArrays.stream().map(strArr -> { strArr[0] = strArr[0].toUpperCase(); return strArr; }); // 打印的的是三个 String[] 引用 chgMapStream.peek(System.out::println).count(); // --------------- flatMap --------------------- // flatMap 方法需要方法返回流类型结果, // 具体返回流是否对输入集合展开,取决方法内部对集合是否做平铺处理 listOfArrays.stream().flatMap(strArray -> { strArray[0].toUpperCase(); // Stream.of(T...) 方法会对传入数组平铺为 T 类型的流 // 此种处理将原始 String[] 展开为 Stream<String> // 后续打印 9 个字符串形成的流 return Stream.of(strArray); // 仅对传入数组转化为 List 类型,并未平铺操作 // 此种处理将原始 String[] 转化为 String<List<String>> // 后续打印就是 3 个 List<String> 形成的流 //return Stream.of(Arrays.stream(strArray).collect(Collectors.toList())); }).peek(System.out::println).count();-
map方法要求处理函数是Function<? super T, ? extends R>,即:- map 给出
T元素,在方法中T 转化为 R,再由 map 封装返回Stream<R>
- map 给出
-
flatMap方法要求处理函数是Function<? super T, ? extends Stream<? extends R>>,即:- flatMap 给出
T元素,在方法中T 转化为 Stream<R>,再由 flatMap 直接返回Stream<R>
flatMap将构成返回的Stream<R>过程完全交由用户map则只要求用户提供元素,封装成流由它处理 - flatMap 给出
-
-
延迟执行,流方法需要执行到 终止方法 后才会被执行,所谓终止方法即返回的非
Stream类型的方法 -
串行流、并行流区别在于后者默认使用 ForkJoin 框架将流在多线程中执行
-
-
Optional
程序运行时可能出现空指针异常(NullPointerException),
Optional类可以解决潜在空指针时繁琐的判空代码。出现空指针的场景:
-
方法返回基本数据类型,但方法返回的是包装类为空值时,拆箱过程抛 NPE
-
数据库查询结果为空
-
集合元素即使
isNotEmpty为真,但不排除其内部元素包含空 -
远程过程调用返回对象可能为空
-
Session中获取数据可能为空 -
级联调用链上,中间调用可能为空
-
将值包装成 Optional
/** * 如果value是null就返回EMPTY,否则就返回of(T) */ public static <T> Optional<T> ofNullable(T value) { return value == null ? empty() : of(value); } /** * 返回Optional对象,要求 value 非空,否则直接抛出 NPE */ public static <T> Optional<T> of(T value) { return new Optional<>(value); } -
map() 和 flatMap()
-
map处理有值的情况,如果有值,则对其执行调用map参数中的函数得到返回值,否则返回空Optional
public static void main(String[] args) { List<String> list = new ArrayList<String>(){ { add("aaa"); add("bbb"); add(null); } }; list.stream().forEach(temp ->{ Optional<String> opt = Optional.ofNullable(temp); System.out.println(opt.map(n -> { return n.toUpperCase(); }).orElse("Nothing")); }); // 简写为如下形式 list.stream().forEach(temp->{ System.out.println(Optional.ofNullable(temp).map(n->n.toUpperCase()).orElse("Nothing")); }); } -
flatMap 如果有值,为其执行mapping函数返回Optional类型返回值,否则返回空Optional。flatMap与map(Funtion)方法类似,区别在于flatMap中的mapper返回值必须是Optional。调用结束时,flatMap不会对结果用Optional封装。
public static void main(String[] args) { Optional<String> opt1 = Optional.ofNullable("aaa"); Optional<String> opt2 = Optional.ofNullable(null); System.out.println(opt1.flatMap(n->{ return Optional.ofNullable(n.toUpperCase()); }).orElse("还会没有吗")); System.out.println( opt2.flatMap(n->{ return Optional.ofNullable(n.toUpperCase()); }).orElse("还会没有吗")); }
-
-
-
Date-Time API
java.time.*包是对java.util.Date强有力的补充,解决了 Date 类的痛点:- 非安全性
- 时区处理麻烦
- 各种格式化、时间计算繁琐
- 设计缺陷,Date 同时包含日期及时间,与
java.sql.Date容易混淆
新日期类主要包含:
-
localDateTime日期 + 时间,格式:yyyy-MM-ddTHH:mm:ss.SSS -
LocalDate日期,格式: yyyy-MM-dd -
LocalTime时间,格式:HH:mm:ss.SSS -
日期时间格式转换
LocalDate date = LocalDate.of(2021, 1, 26); LocalDate.parse("2021-01-26"); LocalDateTime dateTime = LocalDateTime.of(2021, 1, 26, 12, 12, 22); LocalDateTime.parse("2021-01-26 12:12:22"); LocalTime time = LocalTime.of(12, 12, 22); LocalTime.parse("12:12:22"); -
日期计算
public void pushWeek(){ //一周后的日期 LocalDate localDate = LocalDate.now(); //方法1 LocalDate after = localDate.plus(1, ChronoUnit.WEEKS); //方法2 LocalDate after2 = localDate.plusWeeks(1); System.out.println("一周后日期:" + after); //算两个日期间隔多少天,计算间隔多少年,多少月 LocalDate date1 = LocalDate.parse("2021-02-26"); LocalDate date2 = LocalDate.parse("2021-12-23"); Period period = Period.between(date1, date2); System.out.println("date1 到 date2 相隔:" + period.getYears() + "年" + period.getMonths() + "月" + period.getDays() + "天"); //打印结果是 “date1 到 date2 相隔:0年9月27天” //这里period.getDays()得到的天是抛去年月以外的天数,并不是总天数 //如果要获取纯粹的总天数应该用下面的方法 long day = date2.toEpochDay() - date1.toEpochDay(); System.out.println(date1 + "和" + date2 + "相差" + day + "天"); //打印结果:2021-02-26和2021-12-23相差300天 } -
获取指定日期
public void getDayNew() { LocalDate today = LocalDate.now(); //获取当前月第一天: LocalDate firstDayOfThisMonth = today.with(TemporalAdjusters.firstDayOfMonth()); // 取本月最后一天 LocalDate lastDayOfThisMonth = today.with(TemporalAdjusters.lastDayOfMonth()); //取下一天: LocalDate nextDay = lastDayOfThisMonth.plusDays(1); //当年最后一天 LocalDate lastday = today.with(TemporalAdjusters.lastDayOfYear()); //2021年最后一个周日,如果用Calendar是不得烦死。 LocalDate lastSundayOf2021 = LocalDate.parse("2021-12-31").with(TemporalAdjusters.lastInMonth(DayOfWeek.SUNDAY)); } -
JDBC 与 Java 8
java.sql.Date对应java.time.LocalDatejava.sql.Time对应java.time.LocalTimejava.sql.Timestamp对应java.time.LocalDateTime
-
时区
//当前时区时间 ZonedDateTime zonedDateTime = ZonedDateTime.now(); System.out.println("当前时区时间: " + zonedDateTime); //东京时间 ZoneId zoneId = ZoneId.of(ZoneId.SHORT_IDS.get("JST")); ZonedDateTime tokyoTime = zonedDateTime.withZoneSameInstant(zoneId); System.out.println("东京时间: " + tokyoTime); // ZonedDateTime 转 LocalDateTime LocalDateTime localDateTime = tokyoTime.toLocalDateTime(); System.out.println("东京时间转当地时间: " + localDateTime); //LocalDateTime 转 ZonedDateTime ZonedDateTime localZoned = localDateTime.atZone(ZoneId.systemDefault()); System.out.println("本地时区时间: " + localZoned); //打印结果 当前时区时间: 2021-01-27T14:43:58.735+08:00[Asia/Shanghai] 东京时间: 2021-01-27T15:43:58.735+09:00[Asia/Tokyo] 东京时间转当地时间: 2021-01-27T15:43:58.735 当地时区时间: 2021-01-27T15:53:35.618+08:00[Asia/Shanghai]
Java 9
-
JShell
提供一个 Java 版本的实时命令行工具,直接输入 Java 语句并查看执行结果,省去编写
main方法后编译和执行。优点:
- 验证小的逻辑代码块时,免去使用 IDE
- 省去编译执行
- 支持变量重复声明覆盖
-
模块化系统
-
可靠的配置,模块必须声明对其他模块显式依赖,模块化系统验证应用程序开发的所有阶段的依赖关系,编译、链接、运行三个阶段都会进行验证。以往 A 包依赖 B 包,当 B 包缺失时,只能在运行时抛出异常,Java 9 之后在启动时就会由于依赖丢失导致启动失败。
-
强大的封装,Java 9 中 Jar 包中的公共类型并不意味着程序的所有部分都能访问它,增加了更细的可访问控制。Java 9 在编译和运行阶段中间加入链接过程,在链接期间,使用 JDK 9 附带的
jlink工具,用于创建应用程序自定义运行时镜像,其中仅包含应用程序中使用的模块,将运行时大小调整到最佳大小。 -
模块化 JDK/JRE,模块是代码与数据的集合,其中代码可以可以看作零个或多个包的集合,数据可以包括图像、配置等文件等资源。一个模块不仅仅是包的容器,它包括如下内容:
- 所需的其他模块或依赖的列表
- 导出软件包列表(即声明模块的公共 API),其他模块可以使用
- 开放的软件包(模块内整个 API,含公共与私有)到其他反射访问模块的列表
- 使用的服务列表(使用
java.util.ServiceLoader类发现和加载) - 提供的服务的实现列表
Java SE 9 平台包含许多标准模块,它们模块名以
java为前缀,例如:java.base、java.sql、java.xml。非标准平台模块是 JDK 的一部分,但未在 Java SE 平台规范中指定。这些 JDK 特定的模块名以jdk为前缀,例如:jdk.charsets、jdk.compiler、jdk.jlink 等。JDK 特定模块中的 API 不使用与开发人员,这些 API 通常用于 JDK 本身以及不能轻易获得使用 Java SE API 所需功能的库开发人员使用,这些模块中的 API 可能未经通知的情况下对其进行支持或更改。JavaFX 不是 Java SE 9 平台规范的一部分,但在安装 JDK/JRE 时,会安装与 JavaFX 相关的模块。该模块以
javafx为前缀,例如:javafx.base、javafx.controls 等。作为 Java SE 9 平台的一部分,java.base 模块是原始模块,它不依赖任何其他模块。模块系统只知道 java.base 模块,它通过模块中指定的依赖关系发现所有其他模块。java.base 模块导出核心 Java SE 软件包,例如:java.lang、java.io、java.math 等。
-
模块依赖关系
-
将包中的 API 设置为公共,供其他模块使用称为导出包
-
如果模块 A 声明对模块 B 的依赖性,则称之为模块 A 读取 Read B 模块,意味着模块 A 内部可以访问模块 B 导出包中的所有公共类型。此外模块可以选择性的将包导出到一个或多个命名模块,这种称作资格导出 Qualified **或模块友好导出 Module-Friendly**。被资格导出的公共 API 只能被声明的模块访问。
-
三个术语:需要 require、读取 read 和 依赖 depend 是相同含义
// 模块 policy 导出 pkg1 包 module policy { exports pkg1; } // 模块 claim 需要 policy 模块 module claim { requires policy; }
-
-
查看模块的定义描述
# 获取模块定义描述 # java -d 或 --describe-module 模块名 $ java -d java.se java.se@17.0.10 requires java.xml.crypto transitive requires java.base mandated requires java.security.sasl transitive requires java.management transitive requires java.security.jgss transitive requires java.transaction.xa transitive requires java.desktop transitive requires java.instrument transitive requires java.sql.rowset transitive requires java.management.rmi transitive requires java.sql transitive requires java.compiler transitive requires java.logging transitive requires java.scripting transitive requires java.prefs transitive requires java.xml transitive requires java.datatransfer transitive requires java.naming transitive requires java.rmi transitive requires java.net.http transitive -
将模块添加到默认的根模块中,以便解析所添加的模块
# java --add-modules 模块名列表,以逗号分隔 # 模块名还可包含: # ALL-DEFAULT 运行时有效,对于容器应用程序有用,使所有 JavaSE 模块可用于容器 # # ALL-SYSTEM 运行时有效,将系统模块添加到根集中,对于运行测试时非常有用 # # ALL-MODULE-PATH 编译时、运行时有效,模块路径上找到的所有模块添加到根集 # 对 Maven 这样的工具有用 $ java --add-modules ALL-DEFAULT -
聚合模块
假设有几个模块依赖于五个模块,可以将五个模块创建成一个聚合模块,依赖这五个模块的多个模块现在只需依赖这一个聚合模块。像这样创建一个不包括任何代码的模块,仅仅手机并重新导出其他模块的内容的模块,就被称作聚合模块。
-
模块声明
// open 修饰符,可选的,表示声明一个开发的模块,开放模块导出所有包,以便其他模块反射访问 [open] module <module> { <module-statement>; <module-statement>; ... }模块声明示例:
// Declare a module named module module module { // Module statements go here }<module-statement>模块语句包含下面五种:-
导出语句(exports statement)控制访问,允许编译、运行时访问指定包的公共 API
exports <package>; exports <package> to <module1>, <module2>...; -
开放语句(opens statement)控制访问,允许运行时使用反射访问指定包中的所有类型的公共私有成员
opens <package>; opens <package> to <module1>, <module2>...; -
需要语句(requires statement)声明模块对另一模块的依赖
requires <module>; // transitive 表示隐式依赖传递,依赖本模块的其他模块,将也依赖这里声明的 module requires transitive <module>; // static 表示编译时依赖是强制,运行时是可选的 requires static <module>; requires transitive static <module>; -
使用语句(uses statement)服务消费
// 将使本模块使用 Java SPI 加载发现接口 service-interface uses <service-interface>; -
提供语句(provides statement)服务提供
// 声明模块提供服务接口 service-interface 的一个或多个服务实现 provides <service-interface> with <service-impl-class1>, <service-impl-class2>...;
下面以名为
myModule自定义模块声明示例:module myModule { // Exports the packages - com.jdojo.util and // com.jdojo.util.parser exports com.jdojo.util; exports com.jdojo.util.parser; // Reads the java.sql module requires java.sql; // Opens com.jdojo.legacy package for reflective access opens com.jdojo.legacy; // Uses the service interface java.sql.Driver uses java.sql.Driver; // Provides the com.jdojo.util.parser.FasterCsvParser // class as an implementation for the service interface // named com.jdojo.util.CsvParser provides com.jdojo.util.CsvParser with com.jdojo.util.parser.FasterCsvParser; } -
-
模块描述符
-
模块声明存储在名为
module-info.java文件中,该文件存储在模块的源文件层次结构的根目录 -
编译后的文件
module-info.class被称作模块描述符,放在编译代码层次结构的根目录下,若将模块的编译代码打包成 JAR 文件,则模块描述符文件存储在 JAR 文件的根目录下。# 一次编译多个模块,必须将每个模块源码存储在模块名相同的目录下,即时只有一个模块,也遵循此约定 # 目录层次与包层次结构来存储 # 下面是 com.jdojo.contact 模块的编译目录结构 com.jdojo.contact\module-info.java com.jdojo.contact\com\jdojo\contact\info\Address.java com.jdojo.contact\com\jdojo\contact\info\Phone.java com.jdojo.contact\com\jdojo\contact\validator\Validator.java com.jdojo.contact\com\jdojo\contact\validator\AddressValidator.java com.jdojo.contact\com\jdojo\contact\validator\PhoneValidator.java
-
-
打包模块
模块的
artifact可以存储在:-
目录中,例如模块目录
com.jdojo.contact下的文件:module-info.class com\jdojo\contact\info\Address.class com\jdojo\contact\info\Phone.class com\jdojo\contact\validator\Validator.class com\jdojo\contact\validator\AddressValidator.class com\jdojo\contact\validator\PhoneValidator.class -
模块化的 JAR 文件中:
module-info.class com/jdojo/contact/info/Address.class com/jdojo/contact/info/Phone.class com/jdojo/contact/validator/Validator.class com/jdojo/contact/validator/AddressValidator.class com/jdojo/contact/validator/PhoneValidator.class META-INF/MANIFEST.MF -
JMOD 文件中(JDK 9 引入的新模块封装格式)
Java 9 引人的 JMOD 新格式来封装模块,它以
.jmod为扩展名,JDK 模块被编译成为 JMOD 格式,放在 JAVA_HOME\jmods 目录中,例如:JAVA_HOME\jmods\java.base.jmod 则是 java.base 模块的文件路径。此格式仅在编译和链接时才被支持,运行时不受支持
-
-
模块路径
Java 9 引入了一种新的机制来查找模块,被称作模块路径。该路径包含模块的路径名称序列,其路径可以是模块化的 JAR、JMOD 文件或目录的路径。以下是有效的模块路径:
# windows C:\mods C:\mods\com.jdojo.contact.jar;C:\mods\com.jdojo.person.jar C:\lib;C:\mods\com.jdojo.contact.jar;C:\mods\com.jdojo.person.jar # unix /usr/ksharan/mods /usr/ksharan/mods/com.jdojo.contact.jar:/usr/ksharan/com.jdojo.person.jar /usr/ksharan/lib:/usr/ksharan/mods/com.jdojo.contact.jar:/usr/ksharan/mods/com.jdojo.person.jarJava 9 中许多编译运行命令行工具都对模块路径提供了支持选项,以
java命令为例:# 类路径 --class-path # 模块路径 --module-path # 模块版本 --module-version # 主方法 --main-class # 打印模块描述 --print-module-descriptor # windows 下指定模块路径 // Using the GNU-style option C:\>java --module-path C:\applib;C:\lib other-args-go-here // Using the UNIX-style option C:\>java -p C:\applib;C:\extlib other-args-go-here -
可观察模块
模块查找过程中,模块系统使用不同类型的模块路径来定位模块,在模块路径上与系统模块一起发现的一组模块被称作可观察模块。可以将可观察模块视作模块系统在特定阶段可用的所有模块的集合,例如:编译时、链接时或可用于工具。
java命令行工具在 JDK 9 添加了新选项--list-modules,该选项可以打印两种类型的信息:- 可观察模块列表,直接使用
--list-modules - 一个或多个模块的描述,后面追加模块列表
--list-modules moduleName,..
- 可观察模块列表,直接使用
-
-
G1 成默认垃圾回收器
Java 8 默认垃圾收集器是 Parallel Scavenge + Parallel Old,Java 9 之后已经将 CMS 垃圾回收器废弃,同时将 G1 变成为默认垃圾回收器。
-
快速创建不可变集合
增加工厂方法来创建不可变集合,不能对其进行增、删、替换、排序等操作:
List.of("Java", "C++"); Set.of("Java", "C++"); Map.of("Java", 1, "C++", 2); -
String 存储结构优化
Java 9 之后,
String内部将之前的char[]替换为byte[]来存放字符串,节省空间。 -
接口私有方法
public interface MyInterface { private void methodPrivate(){ } } -
try-with-resources 增强
在
try语句中可以存放事实上的不可变变量,之前变量必须放在try语句声明:final Scanner scanner = new Scanner(new File("testRead.txt")); // 后续 writer 变量不被赋值新的对象,即为事实上的 final 变量 PrintWriter writer = new PrintWriter(new File("testWrite.txt")) try (scanner;writer) { // omitted } -
Stream & Optional 增强
-
Stream 增强
// ofNullable(T) Stream<String> stringStream = Stream.ofNullable("Java"); System.out.println(stringStream.count());// 1 Stream<String> nullStream = Stream.ofNullable(null); System.out.println(nullStream.count());//0 List<Integer> integerList = List.of(11, 33, 66, 8, 9, 13); // takeWhile(predicate) 依次取满足条件元素,直到不满足条件结束 integerList.stream().takeWhile(x -> x < 50).forEach(System.out::println);// 11 33 // dropWhile(predicate) 与 takeWhile 相反,获取从第一个不满足条件元素开始的之后所有元素 integerList.stream().dropWhile(x -> x < 50).forEach(System.out::println);// 66 8 9 13 // iterate 重载方法 Stream<T> iterate(final T seed, final UnaryOperator<T> f); // 新增加的重载方法 Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next); // 示例:输出 1~10 // 旧方法 Stream.iterate(1, i -> i + 1).limit(10).forEach(System.out::println); // 新方法 Stream.iterate(1, i -> i <= 10, i -> i + 1).forEach(System.out::println); -
Optional 增强
// ifPresentOrElse,接受两个参数 public void ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction); Optional<Object> objectOptional = Optional.empty(); // Empty!!! objectOptional.ifPresentOrElse(System.out::println, ()->System.out.println("Empty!!!")); // or, 如果 objectOptional 为空,使用 or 中 Supplier 指定的值 public Optional<T> or(Supplier<? extends Optional<? extends T>> supplier); Optional<Object> objectOptional = Optional.empty(); // java objectOptional.or(() -> Optional.of("java")).ifPresent(System.out::println);
-
-
进程 API
增加
java.lang.ProcessHandle接口来实现对原生进程进行管理,尤其适合于管理长时间运行的进程。// 获取当前正在运行的 JVM 的进程 ProcessHandle currentProcess = ProcessHandle.current(); // 输出进程的 id System.out.println(currentProcess.pid()); // 输出进程的信息 System.out.println(currentProcess.info()); -
响应式流
java.util.concurrent.Flow类中新增了反应式流规范的核心接口。Flow.Publisher, 默认实现SubmissionPublisherFlow.SubscriberFlow.SubscriptionFlow.Processor
-
变量句柄
变量句柄 是一个变量或一组变量的引用,包括静态域、非静态域、数组元素和对外数据结构中的组成部分。
变量句柄类似已有的方法句柄
MethodHandle,由 Java 类java.lang.invoke.VarHandle来表示,可以使用类java.lang.invoke.MethodHandles.Lookup中的静态工厂方法来创建VarHandle对象。变量句柄的出现替换了
java.util.concurrent.atomic和sun.misc.Unsafe的部分操作,并提供了一些列标准的内存屏障操作,用于更细粒度的控制内存排序,在安全性、可用性、性能上都要犹豫现有 API。 -
其他
- 平台日志 API 改进:允许为 JDK 和应用配置同样的日志实现。新增
System.LoggerFinder用来管理 JDK 使用的日志记录器实现。JVM 允许时只有一个系统范围的LoggerFinder实例,可以通过添加自定义的该类的实现来让 JDK 和应用使用 SLF4J 等其他日志记录框架 CompletableFuture类增强:新增几个新方法completeAsync、orTimeout等- Nashorn 引擎增强:Java 8 引入的 JavaScript 引擎,Java 9 增强实现了一些 ES6 新特性(Java 11 中已弃用)
- I/O 流新特性:增加新的方法来读取和复制
InputStream中包含的数据 - 改进应用安全性能:新增 4 个 SHA-3 哈希算法:SHA3-224、SHA3-256、SHA3-384 和 SHA3-512
- 改进方法句柄 MethodHandle : 在类
java.lang.invoke.MethodHandles中新增更多静态方法来创建不同类型的方法句柄
- 平台日志 API 改进:允许为 JDK 和应用配置同样的日志实现。新增
Java 10
-
局部变量类型推断
Java 10 提供
var关键字声明局部变量,它并不会改变 Java 是一门静态类型语言的事实,编译器负责类型推断。var id = 0; var codefx = new URL("https://some.web.com/"); var list = new ArrayList<>(); var list = List.of(1, 2, 3); var map = new HashMap<String, String>(); var p = Paths.of("src/test/java/Java9FeaturesTest.java"); var numbers = List.of("a", "b", "c"); for (var n : list) System.out.print(n+ " ");var关键字只能用于带有构造器的局部变量、for 循环中,下面语句将编译不同:var count=null; //❌编译不通过,不能声明为 null var r = () -> Math.random();//❌编译不通过,不能声明为 Lambda表达式 var array = {1,2,3};//❌编译不通过,不能声明数组 -
垃圾回收器接口
通过已入一套纯净的垃圾收集器接口来将不同垃圾收集器的源代码分隔开。
-
G1 并行 Full GC
Java 9 时期的 G1 在 Full GC 使用单线程去完成标记清除算法,耗时长可能在垃圾回收期间由于无法回收内存的时候触发 Full GC,为了最大限度减少 Full GC 造成的停顿影响,G1 现改为并行的标记清除算法,同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少 Full GC 的发生,带来更好的性能及吞吐量。
-
集合增强
List、Set、Map提供静态方法copyOf(),返回入参集合的一个不可变拷贝:static <E> List<E> copyOf(Collection<? extends E> coll) { return ImmutableCollections.listCopy(coll); }java.util.stream.Collectors中新增了静态方法,用于将流中的元素收集为不可变的集合:var list = new ArrayList<>(); list.stream().collect(Collectors.toUnmodifiableList()); list.stream().collect(Collectors.toUnmodifiableSet()); -
Optional 增强
// 在没有值时,抛出指定异常 Optional.ofNullable(cache.getIfPresent(key)) .orElseThrow(() -> new PrestoException(NOT_FOUND, "Missing entry found for key: " + key)); -
应用程序类数据共享(扩展 CDS 功能)
Java 5 中引入的类数据共享(Class Data Sharing)允许将一组类预处理为共享归档文件,运行时能够进行内存映射来减少 Java 程序启动时间,多个 JVM 共享相同归档文件时,还可以减少动态内存占用量,同时减少多个虚拟机在同一个物理或虚拟机的机器上运行的资源占用。
Java 10 允许应用类放置在共享存档中,扩展加入了应用类的 CDS (AppCDS)支持,扩大了 CDS 的使用范围,原理:在启动时记录加载类的过程,写入到文本文件中,再次启动时直接读取次启动文本加载,若应用环境没有大的变化时,启动速度就会得到提升。
-
实验性的基于 Java 的 JIT 编译器
Graal 是一个基于 Java 语言编写的 JIT 编译器,是 JDK 9 加入的实验性 Ahead-of-Time(AOT)编译器的基础。
Oracle 的 HotSpot VM 附带两个 C++ 实现的 JIT Compiler:C1 和 C2。Java 10 (Linux/64、macOS/64)中,默认情况下 HotSpot 仍然使用 C2,但通过添加命令参数
-XX:+UnlockExperimentalVMOptions、-XX:+UseJVMCICompiler参数可将 C2 替换为 Graal。 -
其他
- 线程局部管控:引入 JVM 安全点概念,允许在不允许全局 JVM 安全点的情况下实现线程回调,由线程本身或 JVM 线程来执行,同时保持处于阻塞状态,这种方式使得停止单个线程变成可能,而非只能启用或停止所有线程
- 备用存储装置上的堆分配:JVM 能够使用适用于不同类型的存储机制的堆,在可选内存设备上进行堆内存分配
Java 11 (LTS)
-
Http Client 标准化
Http Client API 在 Java 9 引入,并在 Java 10 中更新,Java 11 正式对此 API 进行了标准化,限制完全支持异步非阻塞。包名由
jdk.incubator.http改为java.net.http,该 API 通过CompleteableFuture提供非阻塞请求和响应语义,使用方式如下:var request = HttpRequest.newBuilder() .uri(URI.create("https://javastack.cn")) .GET() .build(); var client = HttpClient.newHttpClient(); // 同步 HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString()); System.out.println(response.body()); // 异步 client.sendAsync(request, HttpResponse.BodyHandlers.ofString()) .thenApply(HttpResponse::body) .thenAccept(System.out::println); -
String 增强
增加一系列字符串处理方法:
//判断字符串是否为空 " ".isBlank();//true // 去除字符串首尾空格, 只处理空格符 U+0020 // trim() 是码点 ≤ U+0020 的前后都去除 " Java ".strip();// "Java" //去除字符串首部空格 " Java ".stripLeading(); // "Java " //去除字符串尾部空格 " Java ".stripTrailing(); // " Java" //重复字符串多少次 "Java".repeat(3); // "JavaJavaJava" //返回由行终止符分隔的字符串集合。 "A\nB\nC".lines().count(); // 3 "A\nB\nC".lines().collect(Collectors.toList()); -
Optional 增强
var op = Optional.empty(); System.out.println(op.isEmpty());//判断指定的 Optional 对象是否为空 -
ZGC (可伸缩低延迟垃圾收集器)
ZGC 即 Z Garbage Collector,是一个可伸缩的、低延迟的垃圾收集器。
ZGC 主要为了满足如下目标进行设计:
- GC 停顿时间不超过 10ms
- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
- 方便在此基础上引入新的 GC 特性和利用 colored 针以及 Load barriers 优化奠定基础
- 当前只支持 Linux/x64 位平台
ZGC 目前 处在实验阶段,只支持 Linux/x64 平台。
与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
在 ZGC 中出现 Stop The World 的情况会更少!
-
Lambda 参数的局部变量语法
Java 10 中
var关键字存在几个限制:- 只能用于局部变量上
- 声明时必须初始化
- 不能用作方法参数
- 不能在 Lambda 表达式中使用
现在,Java 11 已允许在 Lambda 表达式中使用
var进行参数声明:// 下面两者是等价的 Consumer<String> consumer = (var i) -> System.out.println(i); Consumer<String> consumer = (String i) -> System.out.println(i); -
启动单文件源代码程序
允许运行单一文件的 Java 源代码,后者直接在内存中编译,然后由解析器执行,唯一约束在于所有相关类必须在同一个 Java 文件中,适合于简单程序演示,增强使用 Java 来编写脚本程序的能力。
public class TestOnInFile { public static void main(String[] args) { OneClassInFile ocif = new OneClassInFile(); ocif.sayHello(); } } class OneClassInFile { public void sayHello() { System.out.println("Hello world in One Source File!"); } }使用
java运行源文件:# 直接运行源文件 $ java TestOnInFile.java # 输出 Hello world in One Source File! -
其他
- 新垃圾回收器 Epsilon:一款 No-Op GC (无垃圾收集动作的垃圾回收器),只分配内存,不回收内存。
- 适用场景:
- 学习 GC 的工作方式及实现原理的样例 GC
- 适合生命周期很短的应用,例如:命令行程序、定期启动执行的简单任务
- 对延迟和吞吐量超超级敏感的程序,且程序使用的堆内存有上限
- 做应用的性能测试时,可以排除 GC 的影响
- 测试应用的内存分配上限,若超过指标可以分析 GC 日志找原因,用来优化程序极限内存占用
- 开启参数:
-XX:+UnlockExperimentalVMOptions、-XX:+UseEpsilonGC、-Xlog:gc
- 适用场景:
- 低开销的 Heap Profiling:提供一种低开销的 Java 堆分配采用方法,能够得到对分配的 Java 对象信息,且能够通过 JVM TI (Java Virtual Machine Tool Interface)访问堆信息
- TLS1.3 协议:包含传输层安全性协议 TLS 1.3 规范的实现,替换之前版本中的 TLS、TLS 1.2,同时做了优化
- 飞行记录器(Java Flight Recorder):飞行记录器之前是商业版 JDK 的分析工具,现已开放到公开代码库使用
- 新垃圾回收器 Epsilon:一款 No-Op GC (无垃圾收集动作的垃圾回收器),只分配内存,不回收内存。
Java 12 & 13
-
Java 12
-
String 增强
indent()字符串缩进String text = "Java"; // 缩进 4 格 text = text.indent(4); System.out.println(text); text = text.indent(-10); System.out.println(text); // 输出 Java Javatransform()转变指定字符串int length = "Java".transform(s -> s.length()); System.out.println(length); // 6 -
Files 增强
mismatch()方法匹配两个文件二进制字节流数据,返回第一个不匹配的字节位置,文件相同则返回-1LPath filePath1 = Files.createTempFile("file1", ".txt"); Path filePath2 = Files.createTempFile("file2", ".txt"); Files.writeString(filePath1, "Java 12 Article"); Files.writeString(filePath2, "Java 12 Article"); long mismatch1 = Files.mismatch(filePath1, filePath2); System.out.println(mismatch1); // -1 Path filePath3 = Files.createTempFile("file3", ".txt"); Path filePath4 = Files.createTempFile("file4", ".txt"); Files.writeString(filePath3, "Java 12 文中 Article"); Files.writeString(filePath4, "Java 12 文英 Tutorial"); long mismatch2 = Files.mismatch(filePath3, filePath4); System.out.println(mismatch2); // 11 (第 11 个字节位置,文占用两个字节) -
数字格式化工具类
NumberFormat新增了对复杂数字进行格式化的支持NumberFormat fmt = NumberFormat.getCompactNumberInstance(Locale.US, NumberFormat.Style.SHORT); String result = fmt.format(1000); System.out.println(result); // 1K -
Shenandoah GC
RedHat 主导开发的无暂停式 GC 实现,主要目标是
99.9%的暂停小于10 ms,暂停与堆大小无关。相较于 Java 11 开源的 ZGC,Shenandoah GC 有稳定的 JDK 8 版本,在 Java 8 占据主要市场份额的今天有更大的可落地性。 -
G1 收集器优化
-
可中止的混合收集集合:为了达到用户提供的停顿时间目标,JEP-344 通过把要被回收的区域集(混合收集集合)拆分为强制和可选部分。G1 垃圾回收器为了达到停顿的时间目标,可中止执行可选部分的回收过程。
-
及时返回未使用的已分配内存:JEP-346 的实现,增强 G1 以便在空闲时自动将 Java 堆内存返回给操作系统
-
-
预览新特性
预览新特性,需在
javac、java运行时增加参数--enable-preview激活预览新特性。-
增强
switch,使用类似 lambda 语法,条件匹配成功执行的行快后直接返回,不需要写breakswitch (day) { case MONDAY, FRIDAY, SUNDAY -> System.out.println(6); case TUESDAY -> System.out.println(7); case THURSDAY, SATURDAY -> System.out.println(8); case WEDNESDAY -> System.out.println(9); } -
instanceof模式匹配// 旧版本,匹配成功需要手动强转 Object obj = "我是字符串"; if(obj instanceof String){ String str = (String) obj; System.out.println(str); } // 新版本,直接关键字后声明变量,匹配成功直接使用 Object obj = "我是字符串"; if(obj instanceof String str){ System.out.println(str); }
-
-
-
Java 13
-
增强 ZGC
ZGC 堆由一组称为 ZPages 的堆区域组成,GC 周期中清空 ZPages 区域时,将被释放并返回到页面缓存 ZPageCache 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,结合大小进行组织。
Java 13 中,ZGC 将向操作系统返回被标识为长时间未使用的页面。
-
Socket API 重构
Java 13 将 Socket API 底层进行了重写,
NioSocketImpl替代PlainSocketImpl, 前者使用 JUC 包下的锁而不是同步方法。Java 13 默认使用新的 Socket 实现,也可以设置参数-Djdk.net.usePlainSocketImpl=true来使用旧实现。 -
FileSystems
FileSystems类添加下面三种方法,更容易把文件当做文件系统提供给程序使用:newFileSystem(Path); newFileSystem(Path, Map<String, ?>); newFileSystem(Path, Map<String, ?>, ClassLoader); -
动态 CDS 存档
Java 13 对 Java 10 中引入的应用程序类数据共享(AppCDS)进一步简化、改进和扩展,允许 Java 应用程序执行结束时动态进行类归档,能够被归档的类包括所有已被加载但不属于默认基层 CDS 的应用程序类和引用类库中的类。进一步提高 AppCDS 的可用性,无需用户进行试运行来为每个应用程序创建类列表。
# 初次启动设置归档保存文件路径 java -XX:ArchiveClassesAtExit=my_app_cds.jsa -cp my_app.jar # 再次运行时,指定 AppCDS 归档文件路径,方便快速启动 java -XX:SharedArchiveFile=my_app_cds.jsa -cp my_app.jar -
预览新特性
-
文本块
// 旧版本多行文本字符串 String json ="{\n" + " \"name\":\"mkyong\",\n" + " \"age\":38\n" + "}\n"; // 新文本块形式写法, “"""” 之间的所有字符内容都被解释为字符串的一部分,包括换行符 String json = """ { "name":"mkyong", "age":38 } """; // 旧版本 SQL String query = "SELECT `EMP_ID`, `LAST_NAME` FROM `EMPLOYEE_TB`\n" + "WHERE `CITY` = 'INDIANAPOLIS'\n" + "ORDER BY `EMP_ID`, `LAST_NAME`;\n"; // 新版本 SQL String query = """ SELECT `EMP_ID`, `LAST_NAME` FROM `EMPLOYEE_TB` WHERE `CITY` = 'INDIANAPOLIS' ORDER BY `EMP_ID`, `LAST_NAME`; """;String类新增 3 个方法操作文本块:formatted(Object... args)来支持文本块的格式化设置stripIndent()用于去除文本块中每一行开头和结尾的空格translateEscapes()转义符翻译,例如:"\\t"翻译为"\t"
-
增强
switch(引入yield关键字到 switch 中)switch表达式多了一个关键字yield用于携带一个返回值跳出switch块,它和传统的return语句的区别在于:return会直接跳出当前循环或方法yield只会跳出当前switch块,同时使用yield时,需要有default条件
private static String descLanguage(String name) { return switch (name) { case "Java": yield "object-oriented, platform independent and secured"; case "Ruby": yield "a programmer's best friend"; default: yield name +" is a good language"; }; }
-
-
Java 14 & 15
-
Java 14
-
空指针异常精准提示
添加 JVM 参数
-XX:+ShowCodeDetailsInExceptionMessages可以在发生 NPE 时获取更为详细的调用信息:a.b.c.i = 99; // 假设这段代码会发生空指针 // Java 14 之前 Exception in thread "main" java.lang.NullPointerException at NullPointerExample.main(NullPointerExample.java:5) // Java 14 之后 // 增加参数后提示的异常中很明确的告知了哪里为空导致 Exception in thread "main" java.lang.NullPointerException: Cannot read field 'c' because 'a.b' is null. at Prog.main(Prog.java:5) -
switch增强转正Java 14 对 Java 12 之后陆续引入的
switch增强新特性已从预览特性中转为正式版本,无需额外参数启用。具体特性包含:
- 类似 lambda 语法的条件匹配成功的执行块,无需多写
break yield在代码块中返回值
String result = switch (day) { case "M", "W", "F" -> "MWF"; case "T", "TH", "S" -> "TTS"; default -> { if(day.isEmpty()) yield "Please insert a valid day."; else yield "Looks like a Sunday."; } }; System.out.println(result); - 类似 lambda 语法的条件匹配成功的执行块,无需多写
-
预览新特性
-
record关键字此关键字可以简化数据类(一旦实例化不能修改的类)的定义方式,使用
record代替class定义的类,只需声明属性就可以获得属性的访问方法、toString()、hashCode()和equals()方法。/** * 这个类具有两个特征 * 1. 所有成员属性都是final * 2. 全部方法由构造方法,和两个成员属性访问器组成(共三个) * 那么这种类就很适合使用record来声明 */ final class Rectangle implements Shape { final double length; final double width; public Rectangle(double length, double width) { this.length = length; this.width = width; } double length() { return length; } double width() { return width; } } /** * 1. 使用record声明的类会自动拥有上面类中的三个方法 * 2. 在这基础上还附赠了equals(),hashCode()方法以及toString()方法 * 3. toString方法中包括所有成员属性的字符串表示形式及其名称 */ record Rectangle(float length, float width) { } -
文本块
引入两个新的转义字符:
\表示行尾但不引入换行符、\s表示单个空格String str = "凡心所向,素履所往,生如逆旅,一苇以航。"; String str2 = """ 凡心所向,素履所往, \ 生如逆旅,一苇以航。"""; System.out.println(str2);// 凡心所向,素履所往, 生如逆旅,一苇以航。 String text = """ java c++\sphp """; System.out.println(text); //输出: java c++ php
-
-
其他
- Java 11 引入的 ZGC 作为 G1 过后的下一代 GC 算法,Java 14 开始支持 MacOS 和 Windows
- 移除 CMS 垃圾收集器
- 新增
jpackage工具,除支持将应用打包成 jar 文件外,还支持平台的特性包,例如:Linux 下的deb、rpm,Windows 下的msi、exe
-
-
Java 15
-
CharSequence接口添加默认方法
isEmpty()来判断字符序列是否为空:public interface CharSequence { default boolean isEmpty() { return this.length() == 0; } } -
TreeMap新引入下面这些方法:
putIfAbsent(); computeIfAbsent(); computeIfPresent(); compute(); merge(); -
ZGC 转正
Java 15 开始 ZGC 转为正式版,默认还是 G1,但现在可以直接使用
-XX:+UseZGC来切换 ZGC。 -
EdDSA (数字签名算法)
新加入了一个安全性和性能都更强的基于 Edwards-Curve Digital Signature Algorithm (EdDSA)实现的数字签名算法。
虽然其性能优于现有的 ECDSA 实现,不过,它并不会完全取代 JDK 中现有的椭圆曲线数字签名算法( ECDSA)。
KeyPairGenerator kpg = KeyPairGenerator.getInstance("Ed25519"); KeyPair kp = kpg.generateKeyPair(); byte[] msg = "test_string".getBytes(StandardCharsets.UTF_8); Signature sig = Signature.getInstance("Ed25519"); sig.initSign(kp.getPrivate()); sig.update(msg); byte[] s = sig.sign(); String encodedString = Base64.getEncoder().encodeToString(s); System.out.println(encodedString); // 输出 0Hc0lxxASZNvS52WsvnncJOH/mlFhnA8Tc6D/k5DtAX5BSsNVjtPF4R4+yMWXVjrvB2mxVXmChIbki6goFBgAg== -
文本块转正
Java 15,文本块成为正式的功能特性。
-
隐藏类 (Hidden Classes)
隐藏类是为框架设计的,它不能直接被其他类的字节码使用,只能在运行时生成类并通过反射间接使用它们。
-
预览新特性
-
密封类 Sealed Classes 由 Java 15 引入的新预览特性
该特性之前,要让一个类不能被继承和修改,可以使用
final关键字修饰类,不过此方式也剥夺了该类的继承和修改。密封类通过对继承或实现它们的类进行限制,只被允许指定的类来继承它们,从而既保证相对安全,又具备灵活性:// 抽象类 Person 只允许 Employee 和 Manager 继承。 public abstract sealed class Person permits Employee, Manager { //... }扩展密封类的类本身必须声明为
sealed、non-sealed或finalpublic final class Employee extends Person { } public non-sealed class Manager extends Person { }若允许扩展的子类与封闭类在同一个源代码文件里,封闭类可以不用
permits语句,交由 Java 编译器将为封闭类添加许可的子类。
-
-
其他
- Nashorn JavaScript 引擎彻底移除
- DatagramSocket API 重构
- 禁用和废弃偏向锁:偏向锁引入增加 JVM 的复杂性大于其带来的性能提升,但可使用
-XX:+UseBiasedLocking启用偏向锁,但会提示这是一个已弃用的 API
-
Java 16
-
Vector向量 API该 API 表达一些向量计算,在运行时将被可靠地编译为 CPU 硬件支持的向量指令,充分利用现代 CPU 的单指令多数据(SIMD)技术来获得由于标量计算的性能。Java 16 是该 API 的初始孵化,将在后续版本特性中详细介绍。
-
启用 C++ 14 语义特性
Java 16 允许在 JDK 的 C++ 源码中使用 C++ 14 语言特性,提供在 HotSpot 代码中使用具体指导。
-
ZGC 并发线程堆栈处理
Java 16 将 ZGC 线程栈处理从安全点转移到一个并发阶段,甚至在大堆上也允许在毫秒内暂停 GC 安全点。消除 ZGC 垃圾收集器中最后一个延迟源可以极大地提高应用程序的性能和效率。
-
弹性元空间
此特性可将未使用的 HotSpot 类元数据内存(存储于元空间)更快速地返回操作系统,减少元空间的内存占用。
-
对基于值的类发出警告
- 明确
@Deprecated语义,消除歧义。使用属性since(被弃用时的版本)、forRemoval(是否会被删除) - 原始类型的包装类的构造方法都被标识将来被删除,故鼓励使用自动装箱或静态工厂方法产生包装类实例
- 对值类型使用
synchronized同步块将在编译器和运行期产生警告或异常
- 明确
-
外部内存访问 API
引入外部内存访问 API 以允许 Java 程序安全有效的访问 Java 堆之外的内存,这套 API 的目的:
- 通用:单个 API 可以对各种外部内存(本机内存、持久内存、堆内存等)进行操作
- 安全:无论操作何种内存,API 都不应该破坏 JVM 的安全性
- 控制:可以自由的选择如何释放内存(显式、隐式)
- 可用:如果需要访问外部内存,API 应该是
sun.misc.Unsafe
-
JDK 内部元素默认强封装
-
转正特性
jpackage转正instanceof模式匹配转正record记录类型转正
-
优化改进
- 支持 Unix-Domain 套接字通道:正式支持采用基于文件系统路径名方式而非 IP 地址的方式实现同主机进程间通讯(IPC),提高安全性和效率
- 外部链接器 API:提供纯 Java 访问原生代码的特性,取代以往通过 JNI 方式来粘合代码
Java 17(LTS)
Java 17 是继 Java 8 以来最重要的长期支持(LTS)版本,是 Java 社区八年的努力成果。Java 社区重要的开发框架 Spring 6.x 与 Spring Boot 3.x 最低支持就是 Java 17,所以希望开发人员需要尽快了解该版本及之前的所有特性,以适应不久的将来对 Java 8 的全面替代。
-
增强的伪随机数生成器
Java 17 为伪随机数生成器 PRNG(Pseudo Random Number Generator,又称确定性随机为生成器)增加了新接口类型和实现,方便开发者更容易在应用中切换不同的 PRNG 算法。
示例:
RandomGeneratorFactory<RandomGenerator> l128X256MixRandom = RandomGeneratorFactory.of("L128X256MixRandom"); // 使用时间戳作为随机数种子 RandomGenerator randomGenerator = l128X256MixRandom.create(System.currentTimeMillis()); // 生成随机数 randomGenerator.nextInt(10);之所以称为伪随机,是因为目前的伪随机算法依赖一个初始值(Seed)来生成对应的伪随机数序列。目前,只要是相同的种子,伪随机生成器生成的随机数序列都是确定的,所以不是真正意义上的随机。
-
启用 Applet API
Applet API 用于编写在 Web 浏览器端运行的 Java 小程序,现已经被淘汰了,Java 17 正式删除。
-
switch类型匹配(预览版)switch增加类似instanceof的类型匹配自动转换功能:// Old code static String formatter(Object o) { String formatted = "unknown"; if (o instanceof Integer i) { formatted = String.format("int %d", i); } else if (o instanceof Long l) { formatted = String.format("long %d", l); } else if (o instanceof Double d) { formatted = String.format("double %f", d); } else if (o instanceof String s) { formatted = String.format("String %s", s); } return formatted; } // New code static String formatterPatternSwitch(Object o) { return switch (o) { case Integer i -> String.format("int %d", i); case Long l -> String.format("long %d", l); case Double d -> String.format("double %f", d); case String s -> String.format("String %s", s); default -> o.toString(); }; }对支持对
null值进行判断优化:// Old code static void testFooBar(String s) { if (s == null) { System.out.println("oops!"); return; } switch (s) { case "Foo", "Bar" -> System.out.println("Great"); default -> System.out.println("Ok"); } } // New code static void testFooBar(String s) { switch (s) { case null -> System.out.println("Oops"); case "Foo", "Bar" -> System.out.println("Great"); default -> System.out.println("Ok"); } } -
删除远程方法调用激活机制
删除远程方法调用(RMI)激活机制,同时保留 RMI 的其余部分。
-
密封类转正
介绍参考 Java 14 & Java 15 相应小结
-
删除实验性的 AOT 和 JIT 编译器
删除了基于 Graavl 实现的 AOT 编译器和 JIT 编译器,原因是使用的很少却维护工作量大。
-
弃用安全管理器以进行删除
将
SecurityManager表示为弃用以删除状态,较少使用。
Java 18
-
默认字符集为 UTF-8
Java 17 及之前版本中,Java 虚拟机在运行时才确定默认字符集,而该默认字符集取决于不同的操作系统、区域设置等因素,而 Java 18 已经固定设置默认字符集为 UTF-8,所有支持的操作系统下该版本及之上的 JVM 都保持此默认一致。
-
简易的 Web 服务器
提供命令行工具
jwebserver启动一个简易的静态 Web 服务器:$ jwebserver Binding to loopback by default. For all interfaces use "-b 0.0.0.0" or "-b ::". Serving /cwd and subdirectories on 127.0.0.1 port 8000 URL: http://127.0.0.1:8000/这个服务器不支持 CGI 和 Servlet,只限于静态文件。
-
优化 Java API 文档中的代码片段
之前版本 javadoc 注释中引入代码片段使用:
/** * <pre>{@code * lines of source code * }</pre> **/ public class Test { }效果一般,Java 18 之后,可以通过
@snippet标签来做这件事:/** * The following code shows how to use {@code Optional.isPresent}: * {@snippet : * if (v.isPresent()) { * System.out.println("v: " + v.get()); * } * } */ public class Test { }效果更好,且更易使用。
-
使用方法句柄重新实现反射核心
Java 18 改进了
java.lang.reflect.Method、java.lang.reflect.Constructor实现逻辑,保证 API 不变却获得了更好的性能,其内部使用了方法句柄来进行重构。 -
互联网地址解析 SPI
Java 18 定义了全新的 SPI (Service Provider Interface)用于主要名称和地址的解析,以便
java.net.InetAddress可以使用平台之外的第三方解析器。
Java 19
-
外部函数和内存 API(预览)
该 API 使 Java 程序能够调用本机库并处理本机数据,不像 JNI 那样危险和脆弱。该 API 在 Java 17 中初次孵化后,一直演进到本版本纳入预览版。
- 未引入时现状
- 主要通过
sun.misc.Unsafe提供一些执行低级别、不安全操作的方法,它让 Java 拥有类似 C 指针一样操作内存空间的能力,却带来了 Java 语义不安全性 - JNI 是之前支持原生方法调用的手段,但实现复杂、繁琐,不受 JVM 语言安全机制控制,影响 Java 语言跨平台特性,且性能差强人意
- 主要通过
引入外部函数和内存 API 就是为了解决上述现状,同时提供一套为完备统一安全的 API,主要定义了:
- 操作分配外部内存类:
MemorySegment、MemoryAddress和SegmentAllocator - 操作访问结构化外部内存:
MemoryLayout,VarHandle; - 控制外部内存的分配和释放:
MemorySession - 调用外部函数:
Linker、FunctionDescriptor和SymbolLookup
代码演示:
// 1. 在C库路径上查找外部函数 Linker linker = Linker.nativeLinker(); SymbolLookup stdlib = linker.defaultLookup(); MethodHandle radixSort = linker.downcallHandle( stdlib.lookup("radixsort"), ...); // 2. 分配堆上内存以存储四个字符串 String[] javaStrings = { "mouse", "cat", "dog", "car" }; // 3. 分配堆外内存以存储四个指针 SegmentAllocator allocator = implicitAllocator(); MemorySegment offHeap = allocator.allocateArray(ValueLayout.ADDRESS, javaStrings.length); // 4. 将字符串从堆上复制到堆外 for (int i = 0; i < javaStrings.length; i++) { // 在堆外分配一个字符串,然后存储指向它的指针 MemorySegment cString = allocator.allocateUtf8String(javaStrings[i]); offHeap.setAtIndex(ValueLayout.ADDRESS, i, cString); } // 5. 通过调用外部函数对堆外数据进行排序 radixSort.invoke(offHeap, javaStrings.length, MemoryAddress.NULL, '\0'); // 6. 将(重新排序的)字符串从堆外复制到堆上 for (int i = 0; i < javaStrings.length; i++) { MemoryAddress cStringPtr = offHeap.getAtIndex(ValueLayout.ADDRESS, i); javaStrings[i] = cStringPtr.getUtf8String(0); } assert Arrays.equals(javaStrings, new String[] {"car", "cat", "dog", "mouse"}); // true - 未引入时现状
-
虚拟线程(预览)
虚拟线程(Virtual Thread)是 JDK 而不是操作系统实现的轻量级线程(Lightweight Process), 许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程数量。同等技术已经被其他语言使用并被证实十分有用,例如:Go 的 Goroutine、Erlang 中的进程。它主要避免了上下文的切换损耗,又兼顾多线程的优点,简化了高并发程序的复杂度,可以有效减少编写、维护和观察高吞吐量、高并发应用程序的工作量。
Java 20
-
作用域值(初次孵化)
作用域值(Scoped Values)它可以在线程内和线程间共享不可变的数据,优于线程局部变量,尤其是使用大量虚拟线程时:
final static ScopedValue<...> V = new ScopedValue<>(); // In some method ScopedValue.where(V, <value>) .run(() -> { ... V.get() ... call methods ... }); // In a method called directly or indirectly from the lambda expression ... V.get() ...作用域值允许在大型程序中的组件之间安全有效地共享数据,而无需求助于方法参数。
-
记录模式(第二次预览)
记录模式(Record Patterns)对 record 的值进行解构,也就是更方便地从记录类(Record Class)中提取数据,且可以嵌套记录模式和类型模式结合使用,实现强大的、声明性的、可组合的数据导航和处理形式。
记录模式不能单独使用,需要与
instanceof或switch模式匹配一同使用,下面演示:// 定义 record 类 record Shape(String type, long unit){} Shape circle = new Shape("Circle", 10); // 记录模式运用于 instanceof 模式匹配 if (circle instanceof Shape(String type, long unit)) { System.out.println("Area of " + type + " is : " + Math.PI * Math.pow(unit, 2)); } Shape shape = new Circle(10); switch(shape) { // 记录模式运用于 switch 模式匹配,同时对值进行解构 case Circle(double radius): System.out.println("The shape is Circle with area: " + Math.PI * radius * radius); break; case Square(double side): System.out.println("The shape is Square with area: " + side * side); break; case Rectangle(double length, double width): System.out.println("The shape is Rectangle with area: + " + length * width); break; default: System.out.println("Unknown Shape"); break; }记录模式可以避免不必要的转换,使得代码更简洁易读,此外记录模式不必担心
null或 NPE,代码更安全。 -
switch模式匹配(第四次预览)已在之前版本特性提及,此处省略
-
虚拟线程(第二次预览)
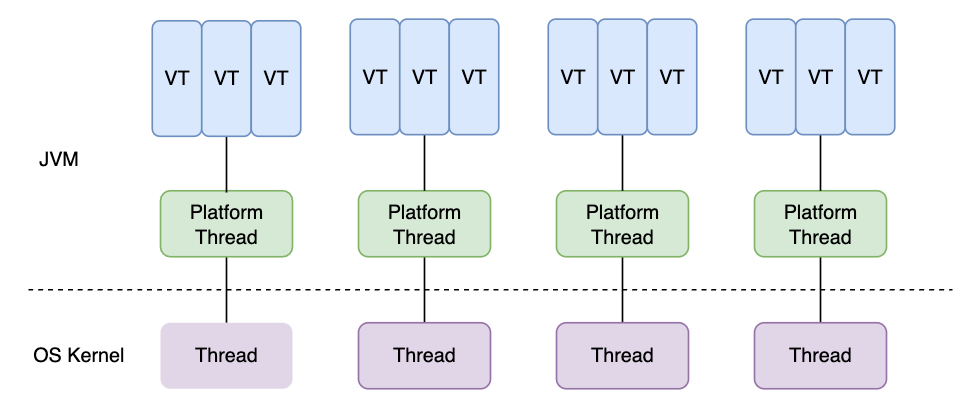
在引入虚拟线程之前,
java.lang.Thread包已经支持所谓的平台线程,也就是没有虚拟线程之前,我们一直使用的线程。JVM 调度程序通过平台线程(载体线程)来管理虚拟线程,一个平台线程可以在不同的时间执行不同的虚拟线程(多个虚拟线程挂载在一个平台线程上),当虚拟线程被阻塞或等待时,平台线程可以切换到执行另一个虚拟线程。Java 在 Windows、Linux 等主流操作系统中使用的是一对一的线程模型,即一个平台线程对应一个系统内核线程,例外的是 Solaris 系统,HotSpot VM 在该平台支持多对多和一对一。
虚拟线程廉价且轻量,用完即可被销毁,不需重用或池化,每个任务可以有自己专属的虚拟线程来运行。它采取暂停恢复来实现线程之间的切换,避免上下文的额外性能损耗。
创建虚拟线程的四种方法:
// 1、通过 Thread.ofVirtual() 创建 Runnable fn = () -> { // your code here }; Thread thread = Thread.ofVirtual(fn) .start(); // 2、通过 Thread.startVirtualThread() 、创建 Thread thread = Thread.startVirtualThread(() -> { // your code here }); // 3、通过 Executors.newVirtualThreadPerTaskExecutor() 创建 var executorService = Executors.newVirtualThreadPerTaskExecutor(); executorService.submit(() -> { // your code here }); class CustomThread implements Runnable { @Override public void run() { System.out.println("CustomThread run"); } } //4、通过 ThreadFactory 创建 CustomThread customThread = new CustomThread(); // 获取线程工厂类 ThreadFactory factory = Thread.ofVirtual().factory(); // 创建虚拟线程 Thread thread = factory.newThread(customThread); // 启动线程 thread.start(); -
结构化并发
Java 19 引入了结构化并发,一种多线程编程方法,目的是为了通过结构化并发 API 来简化多线程编程,并不是为了取代
java.util.concurrent,目前处于孵化器阶段。结构化并发将不同线程中运行的多个任务视为单个工作单元,从而简化错误处理、提高可靠性并增强可观察性。也就是说,结构化并发保留了单线程代码的可读性、可维护性和可观察性。
结构化并发的基本 API 是
StructuredTaskScope,它支持将任务拆分为多个并发子任务,在它们自己的线程中执行,并且子任务必须在主任务继续之前完成。基本用法:
try (var scope = new StructuredTaskScope<Object>()) { // 使用fork方法派生线程来执行子任务 Future<Integer> future1 = scope.fork(task1); Future<String> future2 = scope.fork(task2); // 等待线程完成 scope.join(); // 结果的处理可能包括处理或重新抛出异常 ... process results/exceptions ... } // close结构化并发非常适合虚拟线程,因为虚拟线程轻量级,不像传统线程那样,过多使用时需要池化。
Java 21(LTS)
此版本也是一个重要的 LTS,重要的是将虚拟线程纳入标准。
-
字符串模板(预览)
String Templates 提供了一种更简洁、更直观的方式来动态构建字符串。通过使用占位符
${},我们可以将变量的值直接嵌入到字符串中,而不需要手动处理。// ---------- 字符串模板未引入之前 -------------- //concatenation message = "Greetings " + name + "!"; //String.format() message = String.format("Greetings %s!", name); //concatenation //MessageFormat message = new MessageFormat("Greetings {0}!").format(name); //StringBuilder message = new StringBuilder().append("Greetings ").append(name).append("!").toString(); // -------------- 引入之后 ----------------- String message = STR."Greetings \{name}!";-
STR: 模板处理器,目前支持三种模板处理器:-
STR:自动执行字符串插值,即将模板中的每个嵌入的表达式替换为其值(转换为字符串)
-
FMT:与 STR 类似,但它还可以接受格式说明符,格式说明符出现在表达式左边控制输出样式,
例如:
%-12s\{name} -
RAW:不会自动处理字符串模板,而是返回
StringTemplate对象,包含模板中文本和表达式信息String name = "Lokesh"; //STR String message = STR."Greetings \{name}."; //FMT String message = STR."Greetings %-12s\{name}."; //RAW StringTemplate st = RAW."Greetings \{name}."; String message = STR.process(st);此外,支持实现
StringTemplate.Processor接口可以自定义自己的模板处理器
-
-
\{name}:表达式,运行时被相应变量值替换
表达式可以使用局部变量、静态/非静态字段、方法、逻辑运算作为嵌入表达式:
//variable message = STR."Greetings \{name}!"; //method message = STR."Greetings \{getName()}!"; //field message = STR."Greetings \{this.name}!"; // 运算表达式 int x = 10, y = 20; String s = STR."\{x} + \{y} = \{x + y}"; //"10 + 20 = 30"嵌入表达式还可分成多行:
String time = STR."The current time is \{ //sample comment - current time in HH:mm:ss DateTimeFormatter .ofPattern("HH:mm:ss") .format(LocalTime.now()) }."; -
-
序列化集合
JDK 21 引入了一种新的集合类型:Sequenced Collections(序列化集合,也叫有序集合),这是一种具有确定出现顺序(encounter order)的集合(无论我们遍历这样的集合多少次,元素的出现顺序始终是固定的)。
主要接口:
SequencedCollection、SequencedSet、SequencedMapSequencedCollection主要方法:interface SequencedCollection<E> extends Collection<E> { // New Method SequencedCollection<E> reversed(); // Promoted methods from Deque<E> void addFirst(E); void addLast(E); E getFirst(); E getLast(); E removeFirst(); E removeLast(); } // List、Deque 接口实现了这个接口SequencedSet接口直接继承了SequencedCollection并重写了reversed()方法:interface SequencedSet<E> extends SequencedCollection<E>, Set<E> { SequencedSet<E> reversed(); } // SortedSet、LinkedHashSet 实现了这个接口SequencedMap接口继承Map接口,提供在集合两端访问、添加、删除键值对,获取包含 key 的SequencedSet、包含 value 的SequencedCollection, 包含 entry 键值对的SequencedSet以及获取集合反向试图的方法:interface SequencedMap<K,V> extends Map<K,V> { // New Methods SequencedMap<K,V> reversed(); SequencedSet<K> sequencedKeySet(); SequencedCollection<V> sequencedValues(); SequencedSet<Entry<K,V>> sequencedEntrySet(); V putFirst(K, V); V putLast(K, V); // Promoted Methods from NavigableMap<K, V> Entry<K, V> firstEntry(); Entry<K, V> lastEntry(); Entry<K, V> pollFirstEntry(); Entry<K, V> pollLastEntry(); } // SortedMap LinkedHashMap 实现了这个接口 -
分代 ZGC
Java 21 对 ZGC 进行了功能扩展,增加分代 GC 功能,默认关闭,参数
-XX:+ZGenerational打开支持。未来版本中 ZGC 将默认打开分代支持,最终移除非分代的 ZGC。 -
记录模式
正式转正
-
switch模式匹配正式转正
-
虚拟线程
正式转正
-
未命名模式和变量(预览)
未命名模式和变量使得我们可以使用下划线
_表示未命名的变量以及模式匹配时不使用的组件,旨在提高代码的可读性和可维护性。未命名变量的典型场景是
try-with-resources语句、catch子句中的异常变量和for循环。当变量不需要使用的时候就可以使用下划线_代替,这样清晰标识未被使用的变量。try (var _ = ScopedContext.acquire()) { // No use of acquired resource } try { ... } catch (Exception _) { ... } catch (Throwable _) { ... } for (int i = 0, _ = runOnce(); i < arr.length; i++) { ... }未命名模式是一个无条件的模式,并不绑定任何值。未命名模式变量出现在类型模式中。
if (r instanceof ColoredPoint(_, Color c)) { ... c ... } switch (b) { case Box(RedBall _), Box(BlueBall _) -> processBox(b); case Box(GreenBall _) -> stopProcessing(); case Box(_) -> pickAnotherBox(); } -
未命名类和实例 main 方法(预览)
这个特性主要简化了
main方法的的声明。对于 Java 初学者来说,这个main方法的声明引入了太多的 Java 语法概念,不利于初学者快速上手。class HelloWorld { // 使用未命名特性定义的 main 方法 void main() { System.out.println("Hello, World!"); } }进一步精简(未命名的类允许不定义类名):
void main() { System.out.println("Hello, World!"); }
推荐阅读






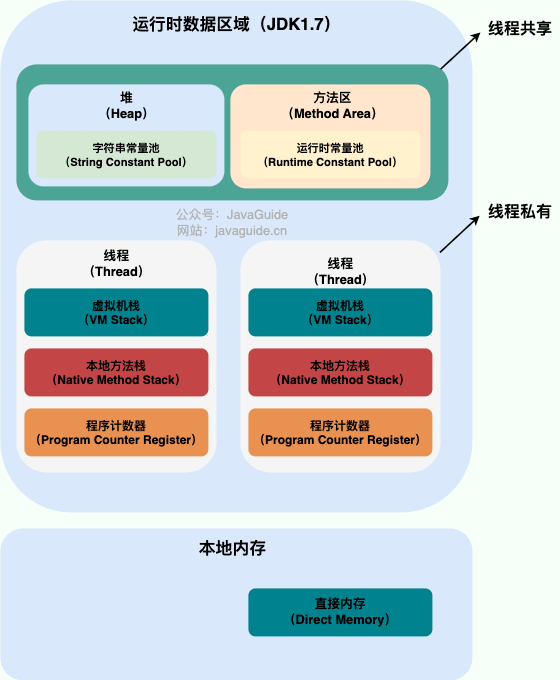{kind=link}
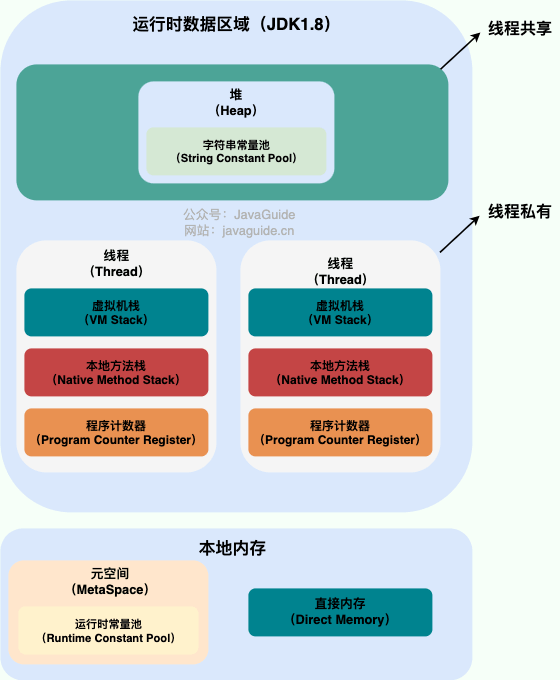{kind=link}
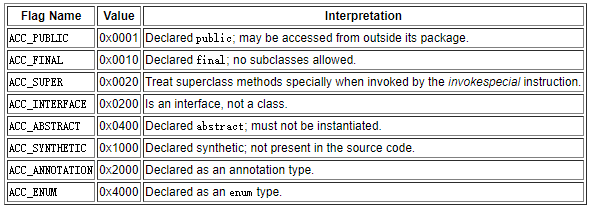{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
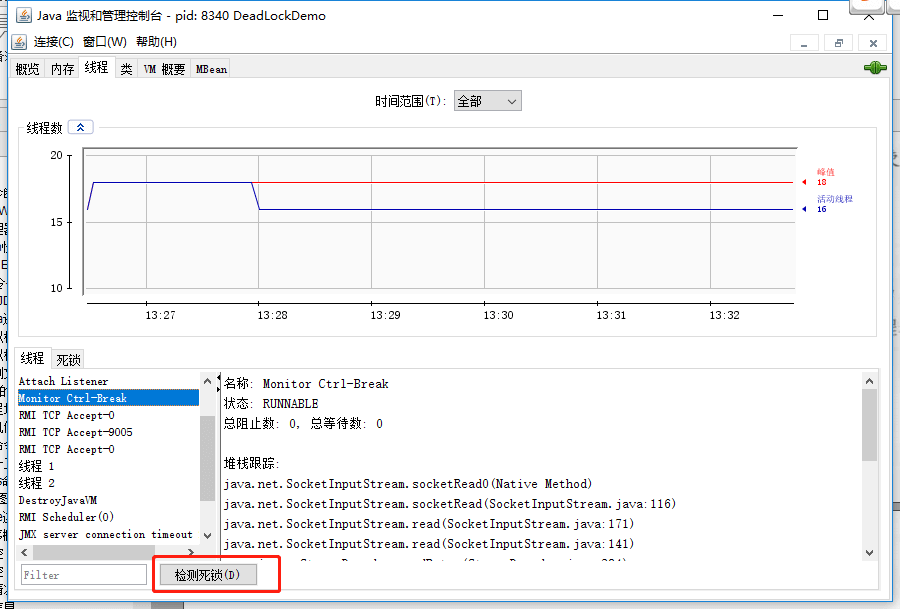{kind=link}
{kind=link}
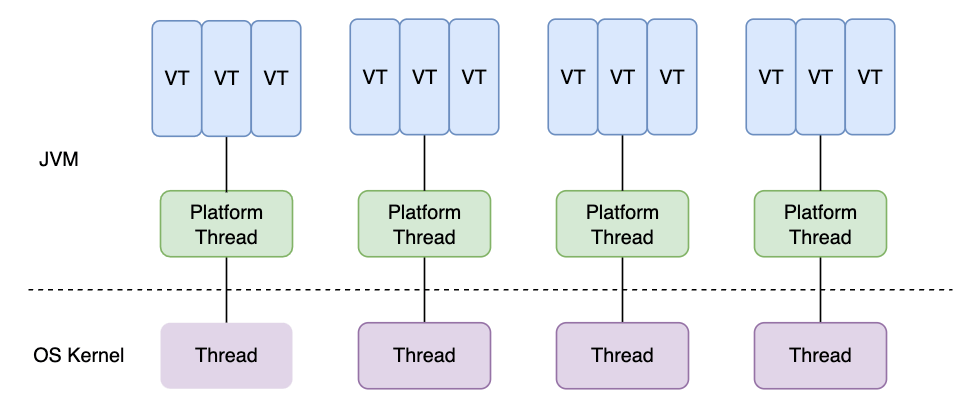{kind=link}